You may not know about brownouts, blackouts and dirty pages in Hyper-V Live Migrations, but they are useful for monitoring virtual machine live migration
Hyper-V Live Migration is undoubtedly the most sought-after feature of Hyper-V because of its ability to move virtual machines (VMs) between clustered hosts without noticeable service interruption. But in fact, Live Migration can cause brief disruptions in service that end users may not notice.
As an admin, you should understand some lesser-known Hyper-V Live Migration terms that help monitor and troubleshoot service interruption.
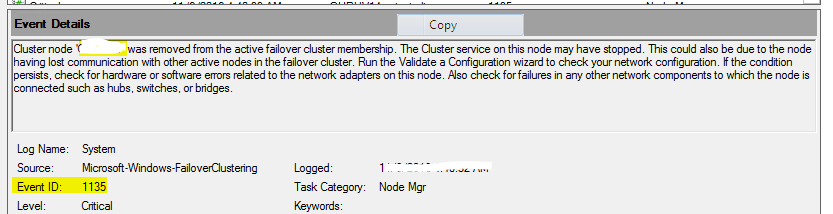
Hyper-V event logs contain information about live migration disruptions that can briefly affect VMs. For every VM live migration, these logs report three events: a brownout event, a blackout and dirty-pages event, and a summary of the live-migration process. Understanding these terms also helps you troubleshoot live migrations that take too long and prevent administrative tasks
You’ll find the Live Migration logs in the Application and Services Log -> Microsoft -> Windows -> Hyper-V-Worker
These Hyper-V Live Migration terms are numbered as follows:
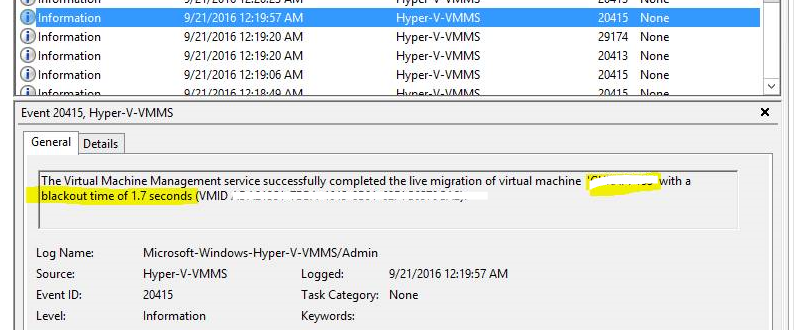
A Live Migration brownout event
A Hyper-V-Worker event log lists the brownout stage first. In the context of virtualization, a brownout is defined as the amount of time it takes to complete the memory-transfer portion of Hyper-V Live Migration. And the term brownout is a good metaphor for this event, because a VM is not affected completely (as the term blackout suggests). The VM is still responsive, but you can’t perform configuration changes or other administrative functions during this stage of the live migration
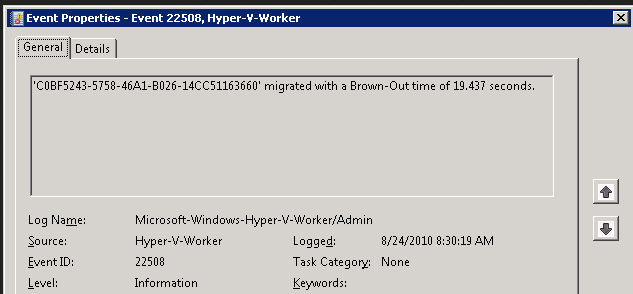
Above figure indicates that the brownout took 19.43 seconds. This time depends on the size of active RAM the VM uses and the speed of the Live Migration transport network. During this time, the VM is completely responsive as the memory pages move to the destination node. This stage of live migration gets most of a VM’s state over to another node, but not quite all. Since the VM is responsive, users most likely never know that a migration to another node is in process. But VM response may get delayed. You can monitor this delay by constantly pinging the VM with the command ping SERVERNAME –t. You’ll notice brief periods of longer response times, without total disruption of service
Live Migration blackout and dirty-pages event
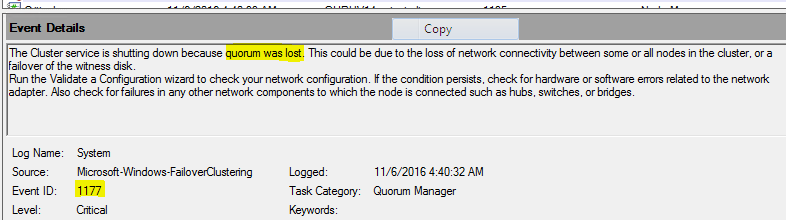
The final stage in Hyper-V Live Migration is when a VM fully migrates to the destination node of the cluster. This process is called the blackout stage, where, to finally move a VM and all its memory, there is a brief pause in service. During the brownout stage, the host attempts to move all active memory to the destination node. But server memory isn’t completely emptied until this final process, where data is moved to the destination node. A final snapshot provides a last file representation of the remaining memory, which is known as dirty pages. When dirty pages are migrated to the destination node, the blackout occurs.
The blackout period is by no means comparable to the longer saved state in Hyper-V’s former Quick Migration feature, because Live Migration usually moves a very small amount of data during this final stage. But a slight disruption will occur, usually about one to two seconds, or one dropped ping. Unlike during the brownout stage, a VM is not responsive. The event log indicates how long the blackout period was and how many dirty pages were moved during the migration’s final stage (see below Figure)
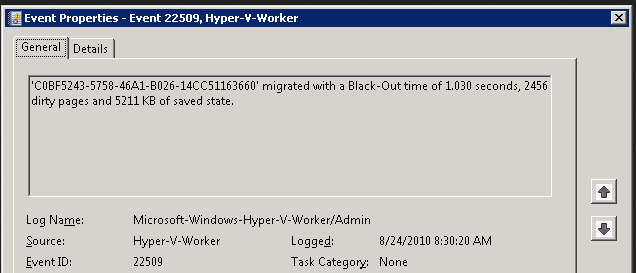
Note that during a live migration for servers with a higher transaction workload, longer blackout times and a greater number of dirty pages occur.
These two Hyper-V Live Migration terms are important, because the blackout and dirty-pages event are troubleshooting tools. The log tells you for how long a VM was unavailable, which is useful information when a live migration takes longer than expected or when there is a noticeable disruption in service
Live Migration summary event
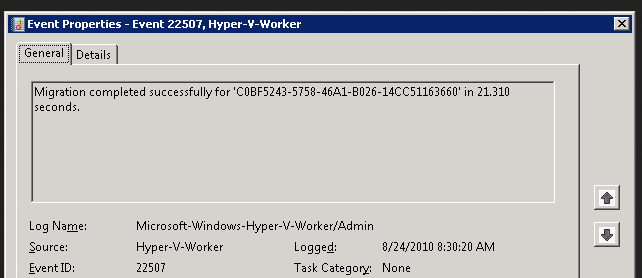
The final event, 22507, gives a nice summary of the duration of the live migration process
Note: Above article written based on Hyper-v 2008 r2 and it is applicable to later version too..