Below script used to assign NTFS permissions( List,Read,Traverse, Create/Append) for FSlogix user profiles, it provides users not to access other folders
#Below script used to assign NTFS permissions( List,Read,Traverse, Create/Append) for FSlogix user profiles, it provides users not to access other folders
# User Groups/Users are given in input file , Keep Heading(top) GROUPS and provide groupnames under that
# Input your Storage account name and Domain Name in below script
# Whoever runs the below code, he should have full admin privilege
$permission = ":(X,RD,AD,RC)"
$Lists = Import-csv -Path "C:\temp\devgroups.csv" #group Accounts
$shares = "<Share Name 1>,<Share Name 2>"
$sharelist = $shares.Split(",")
foreach($share in $sharelist)
{
$share
$shrpath=\\<storageAccountName>.file.core.windows.net\$share
foreach($list in $lists)
{
$UserName = $list.groups
Invoke-Expression -Command ('icacls $shrpath /grant "<Domain Name>\${UserName}${permission}"')
}
}
We had a requirement to migrated 8000+ Citrix User UPM profiles across globe to FSLogix Profiles (.VHDX) as customer wanted to move from Citrix to AVD. This was a very challenging requirement due to new experience
Post Virtual Machine Deletion in Azure, few resources like Disk,NICs,NSG,Public IP etc.. will remain exists so use below script to cleanup all these orphaned resources
## Gather orphaned resources details using below link and use below script to delete all orphaned resources
https://github.com/scautomation/AzureResourceGraph-Examples/blob/master/resourceQueries/Orphaned%20Resources/OrphanedResource.MD
##########################DeleteOrphanedDisk##########################
$csv = Import-Csv "disk.csv" #name of csv file
$filetim = (Get-Date).tostring("dd-MM-yyyy-hh-mm")
$Logfile = "log-deletedisk-$filetim.log"
Function LogWrite
{
Param ([string]$logstring)
Add-content $Logfile -value $logstring
}
Start-Transcript -Path $Logfile
Stop-Transcript
LogWrite " "
LogWrite " "
LogWrite "***** LogFile *****"
LogWrite " "
LogWrite " "
$csv | ForEach-Object {
$diskname = $_.NAME
$state = $_.DISKSTATE
$resourcegroup = $_.RESOURCEGROUP
$location = $_.LOCATION
if($state -like "Unattached")
{
$tim = (Get-Date).tostring("dd-MM-yyyy-hh:mm:ss")
LogWrite "$tim - Deleting disk $diskname in $resourcegroup of Location - $location"
Write-Host -ForegroundColor Cyan "Deleting Disk $diskname in $resourcegroup of Location - $location"
Remove-AzDisk -ResourceGroupName $resourcegroup -DiskName $diskname -Force
}
else
{
Write-Host -ForegroundColor Red "Failed to delete the disk $diskname in $resourcegroup of Location - $location since it is Attached"
$tim = (Get-Date).tostring("dd-MM-yyyy-hh:mm:ss")
LogWrite "$tim - Failed to delete the disk $diskname in $resourcegroup of Location - $location since it is Attached"
}
}
#####################################################################
##########################DeleteOrphanedNICs##########################
$csv = Import-Csv "nic.csv" #name of csv file
$filetim = (Get-Date).tostring("dd-MM-yyyy-hh-mm")
$Logfile = "log-$filetim.log"
Function LogWrite
{
Param ([string]$logstring)
Add-content $Logfile -value $logstring
}
Start-Transcript -Path $Logfile
Stop-Transcript
LogWrite " "
LogWrite " "
LogWrite "***** LogFile *****"
LogWrite " "
LogWrite " "
$csv | ForEach-Object {
$nicname = $_.NAME
$resourcegroup = $_.RESOURCEGROUP
$location = $_.LOCATION
$tim = (Get-Date).tostring("dd-MM-yyyy-hh:mm:ss")
LogWrite "$tim - Deleting NIC $nicname in $resourcegroup of Location - $location"
Write-Host -ForegroundColor Cyan "Deleting NIC $nicname in $resourcegroup of Location - $location"
Remove-AzNetworkInterface -Name $nicname -ResourceGroup $resourcegroup -Force
}
#####################################################################
##########################DeleteOrphanedNSGs#########################
$csv = Import-Csv "nsg.csv" #name of csv file
$filetim = (Get-Date).tostring("dd-MM-yyyy-hh-mm")
$Logfile = "log-deleteNSG-$filetim.log"
Function LogWrite
{
Param ([string]$logstring)
Add-content $Logfile -value $logstring
}
Start-Transcript -Path $Logfile
Stop-Transcript
LogWrite " "
LogWrite " "
LogWrite "***** LogFile *****"
LogWrite " "
LogWrite " "
$csv | ForEach-Object {
$nsgname = $_.RESOURCE
$resourcegroup = $_.RESOURCEGROUP
$location = $_.LOCATION
$tim = (Get-Date).tostring("dd-MM-yyyy-hh:mm:ss")
LogWrite "$tim - Deleting NSG $nsgname in $resourcegroup of Location - $location"
Write-Host -ForegroundColor Cyan "Deleting NSG $nsgname in $resourcegroup of Location - $location"
Remove-AzNetworkSecurityGroup -Name $nsgname -ResourceGroup $resourcegroup -Force
}
#####################################################################
##########################DeleteOrphanedPiP##########################
$csv = Import-Csv "pip.csv" #name of csv file
$filetim = (Get-Date).tostring("dd-MM-yyyy-hh-mm")
$Logfile = "log-deletePIP-$filetim.log"
Function LogWrite
{
Param ([string]$logstring)
Add-content $Logfile -value $logstring
}
Start-Transcript -Path $Logfile
Stop-Transcript
LogWrite " "
LogWrite " "
LogWrite "***** LogFile *****"
LogWrite " "
LogWrite " "
$csv | ForEach-Object {
$pipname = $_.NAME
$resourcegroup = $_.RESOURCEGROUP
$location = $_.LOCATION
$tim = (Get-Date).tostring("dd-MM-yyyy-hh:mm:ss")
LogWrite "$tim - Deleting Public IP $pipname in $resourcegroup of Location - $location"
Write-Host -ForegroundColor Cyan "Deleting Public IP $pipname in $resourcegroup of Location - $location"
Remove-AzPublicIpAddress -Name $pipname -ResourceGroupName $resourcegroup -Force
}
#####################################################################
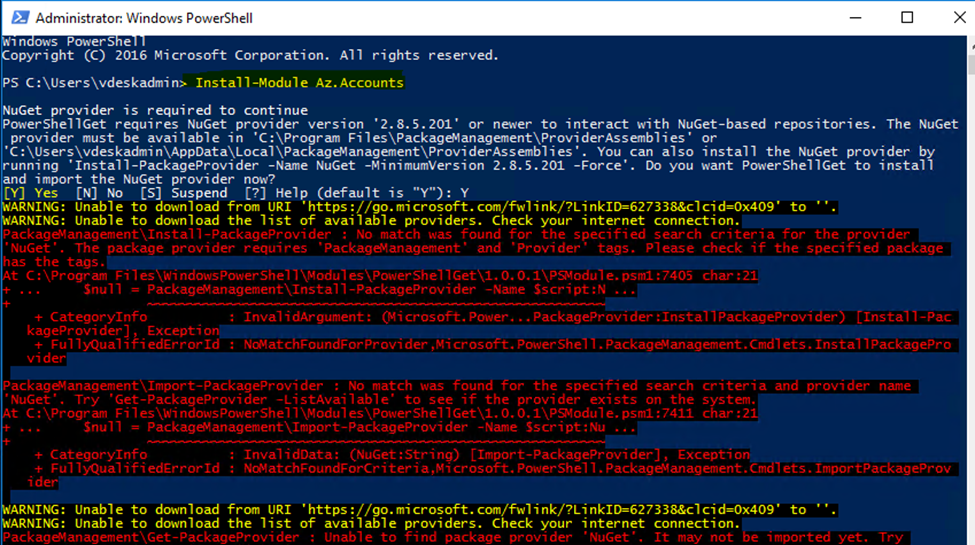
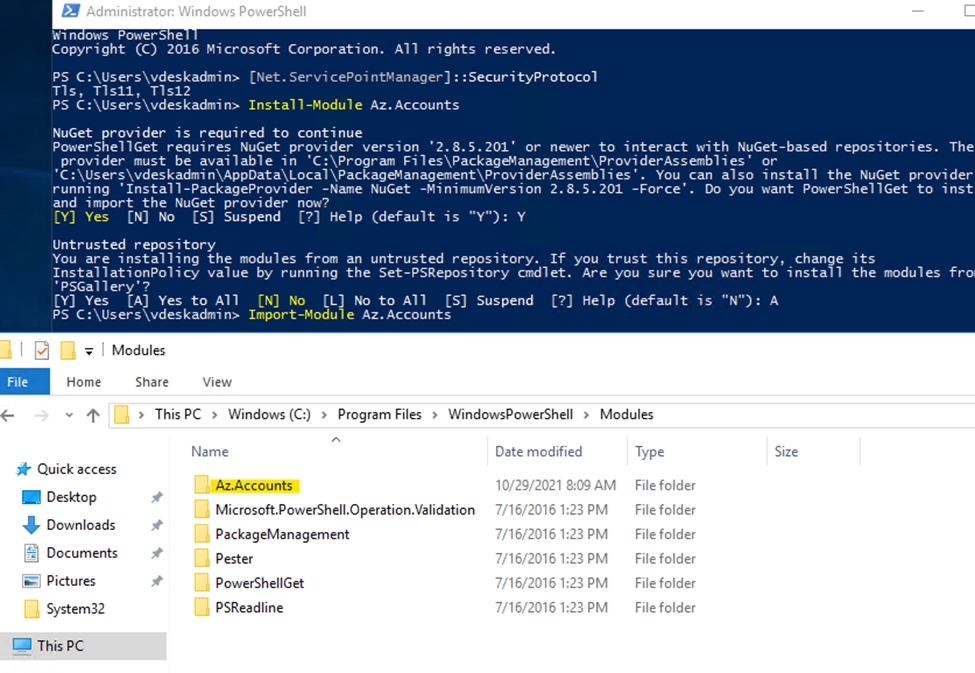
We need to install the Azure PowerShellGet module. The problem is that we are unable to install NuGet provider and a couple of errors are showing. Warning unable to download from URI, unable to download the list of available providers. After the errors, it did not install. In this article, you will learn why this is happening and the solution for installing NuGet provider for PowerShell.
Install-Module Az.Accounts
Based on above error, tried below commands to install NuGet Provider for Powershell
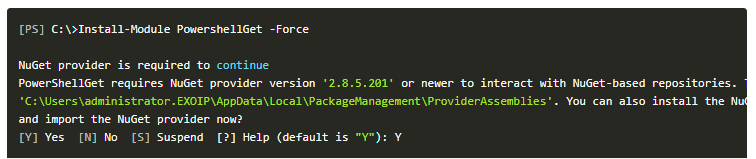
Run PowerShell as administrator. Run the command Install-Module PowershellGet -Force. When asked to install NuGet provider, press Y and follow with Enter.
After pressing Y and follow with Enter, the output is giving us the following warnings.
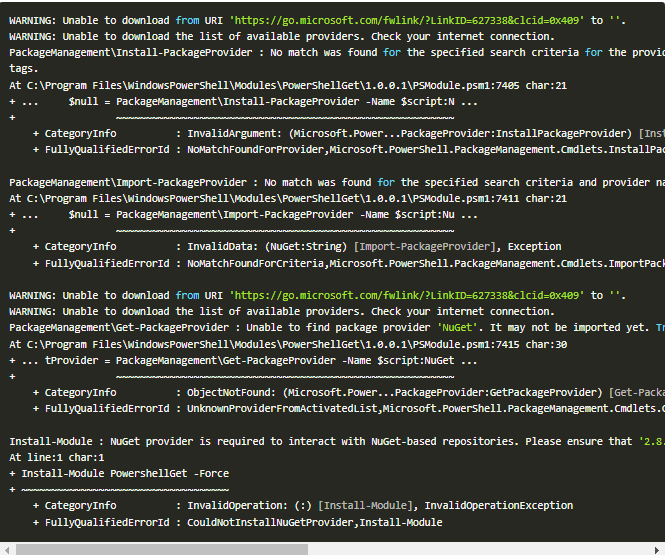
WARNING: Unable to download from URI.
WARNING: Unable to download the list of available providers. Check your internet connection.
Unable to find package provider ‘NuGet’. It may not be imported yet.
OR , you will not able t
Why are we getting this error and what is the solution for unable to install and download NuGet provider?
Find PowerShell version
Find the PowerShell version that is running on the system. We are going to use the Get-Host cmdlet in Windows Server 2016.
Check Transport Layer Security protocols
PowerShell 5.1 enables SSL 3.0 and TLS 1.0 for secure HTTP connections by default. Let’s confirm that with the next step.
Check the supported security protocols on the system.
As we can see, the security protocols defined in the system are SSL 3.0 and TLS 1.0. Both of the security protocols are deprecated.
Follow below steps to resolve the above error
First, check the SSL version with below command
Solution for unable to install NuGet provider for PowerShell
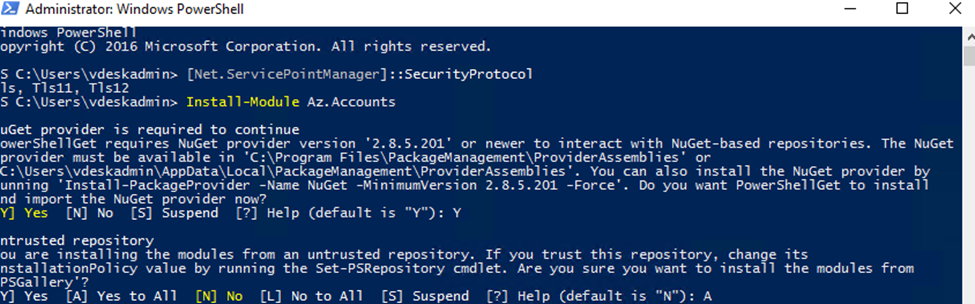
Now that we gathered all the information, we are going to enable TLS 1.2 on the system. Run both cmdlets to set .NET Framework strong cryptography registry keys. After that, restart PowerShell and check if the security protocol TLS 1.2 is added
The first cmdlet is to set strong cryptography on 64 bit .Net Framework (version 4 and above).
Restart Powershell and check for supported security protocols.
Run again Install-Module Az.Accounts
Post installation, Import Modules ( Installed Modules can be seen in C:\Program Files\WindowsPowerShell\Modules)
Similarly do for Azure storage modules
Conclusion:
In this article, we learned why we are unable to install Azure &NuGet provider for PowerShell. The solution to this problem is configuring TLS1.2 or higher on the system. After that, you can install NuGet & Azure Modules for PowerShell
Azure Files offers fully managed file shares in the cloud that are accessible via the industry standard Server Message Block (SMB) protocol or Network File System (NFS) protocol. Azure Files file shares can be mounted concurrently by cloud or on-premises deployments. SMB Azure file shares are accessible from Windows, Linux, and macOS clients. NFS Azure Files shares are accessible from Linux or macOS clients. Additionally, SMB Azure file shares can be cached on Windows Servers with Azure File Sync for fast access near where the data is being used
Why would I use an Azure file share versus Azure Blob storage for my data?
Azure Files and Azure Blob storage both offer ways to store large amounts of data in the cloud, but they are useful for slightly different purposes. Azure Blob storage is useful for massive-scale, cloud-native applications that need to store unstructured data. To maximize performance and scale, Azure Blob storage is a simpler storage abstraction than a true file system. You can access Azure Blob storage only through REST-based client libraries (or directly through the REST-based protocol).
Azure Files is specifically a file system. Azure Files has all the file abstracts that you know and love from years of working with on-premises operating systems. Like Azure Blob storage, Azure Files offers a REST interface and REST-based client libraries. Unlike Azure Blob storage, Azure Files offers SMB or NFS access to Azure file shares. File shares can be mounted directly on Windows, Linux, or macOS, either on-premises or in cloud VMs, without writing any code or attaching any special drivers to the file system. You also can cache Azure SMB file shares on on-premises file servers by using Azure File Sync for quick access, close to where the data is used.
For a more in-depth description on the differences between Azure Files and Azure Blob storage, see Introduction to the core Azure Storage services. To learn more about Azure Blob storage, see Introduction to Blob storage.
Azure Files Connectivity options
We have some different connectivity options available to us depending on whether we’re accessing our file shares either internally or externally. In this context, accessing it internally or externally implies the Azure region where our storage account exists, where the file share exists.
• Internal connectivity: This implies that the clients accessing the file share are within the Azure cloud itself. Here we have the ability to use REST, SMB 2.1 and SMB 3.0.
• External connectivity: In this scenario, the client machines accessing the file shares are located in a different cloud environment or could also reside on premises. We only have the option of using REST and SMB 3.0 in this case because SMB 2.1 doesn’t provide the encryption which is required for connecting externally to ensure the safety of the data.
In terms of security, data encrypted at rest by default within our storage accounts and we have access to secure data transfer over HTTPS for data that is in transit. This allows us to protect our data, whether it’s at rest or in transit inside of our Azure Files.
Creating an Azure File Share Prerequisites
Create a storage account
Traditional AD environment synchronized to Azure AD with Azure AD Connect
Account credentials to perform the steps below to create a computer account in an existing Active Directory environment to connect with Azure Files.
Permissions to create the storage account
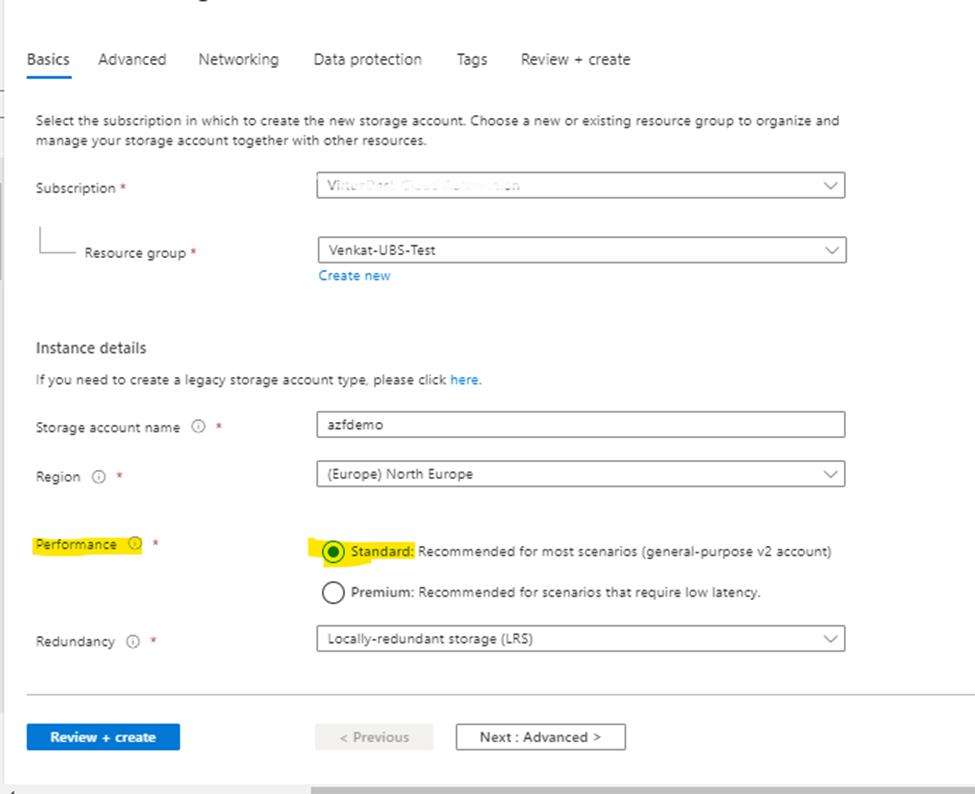
Before you can work with an Azure file share, you have to create an Azure storage account. A general-purpose v2 storage account provides access to all of the Azure Storage services: blobs, files, queues, and tables.
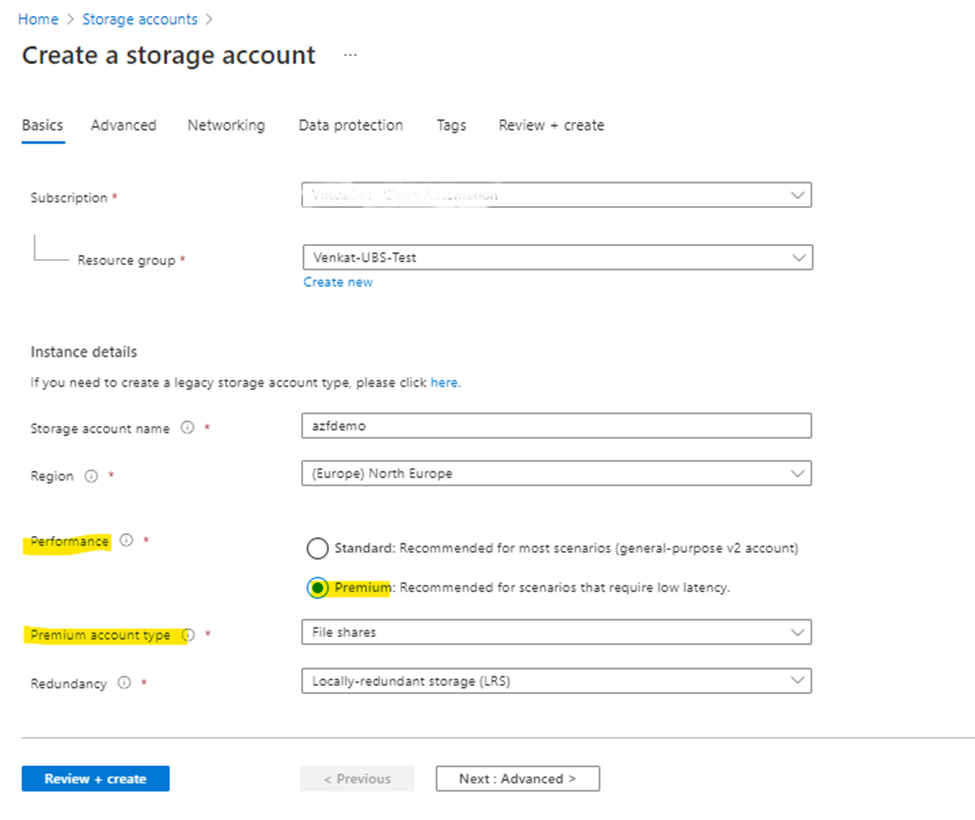
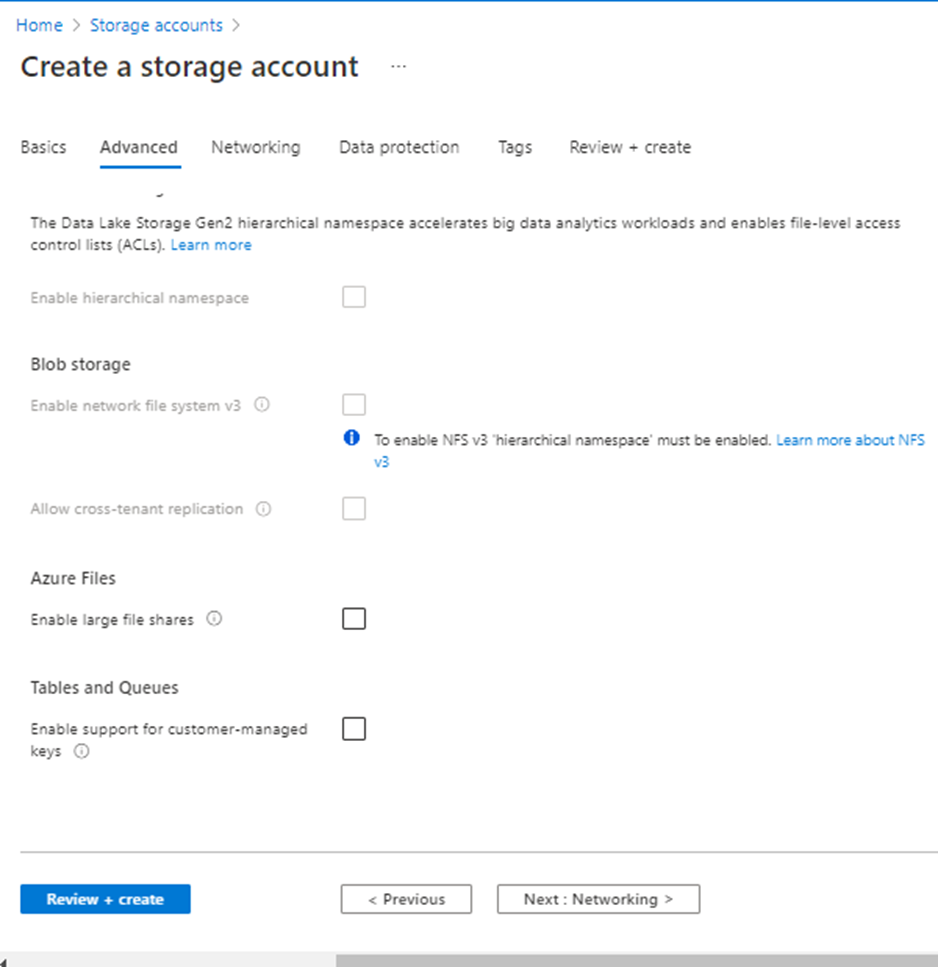
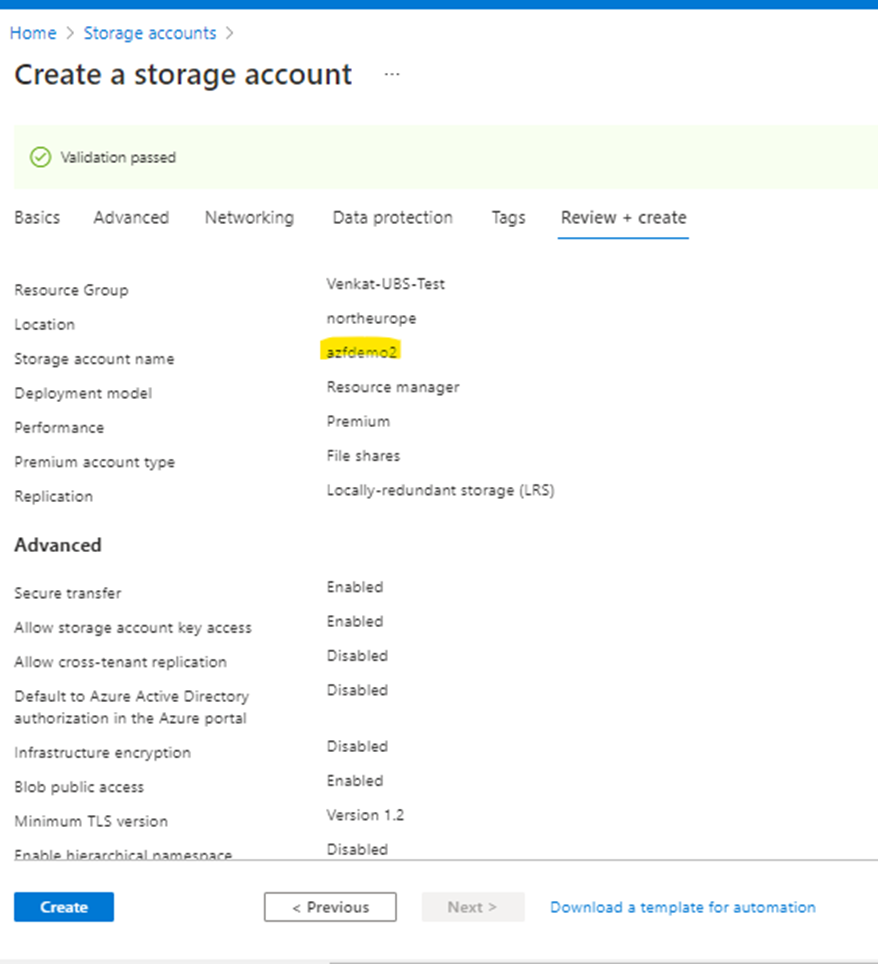
As I have a requirement for Premium, below screenshots are provided with Premium Type and note that options may vary based on selection of storage account type.
Storage Accounts ->Create New
In above screenshot, I selected Performance Type as “Standard”. In case, if you have a requirement for Premium file Type then options will be displayed as below
Click Next (Default options)
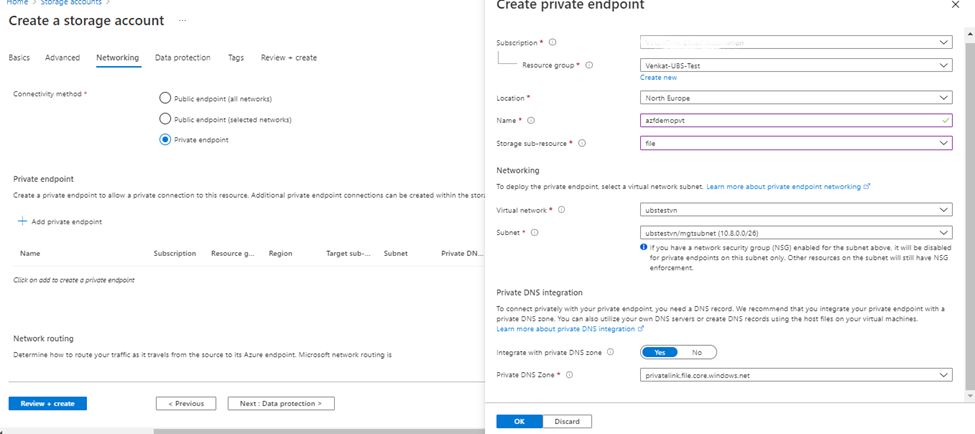
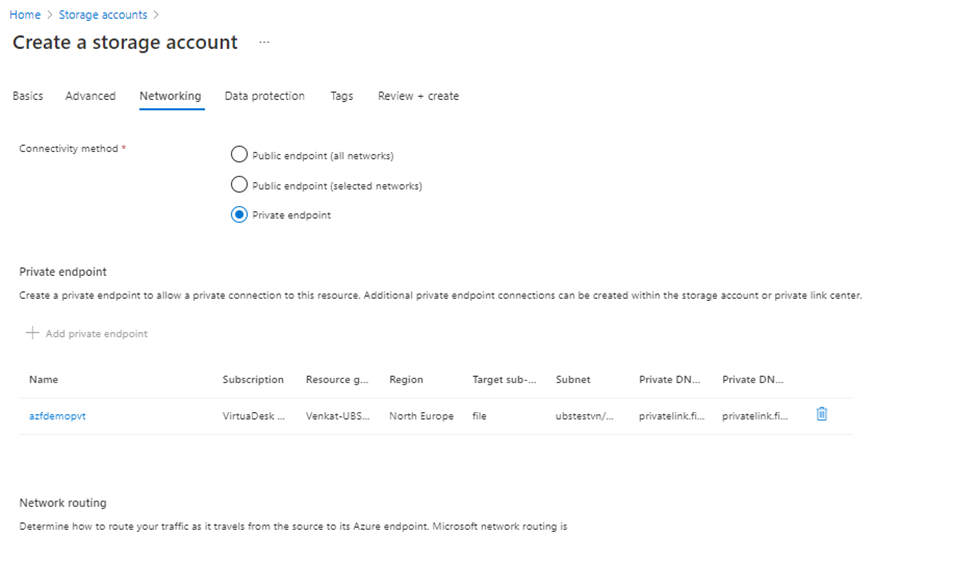
Under Networking ->Create Private Endpoint (best practice)
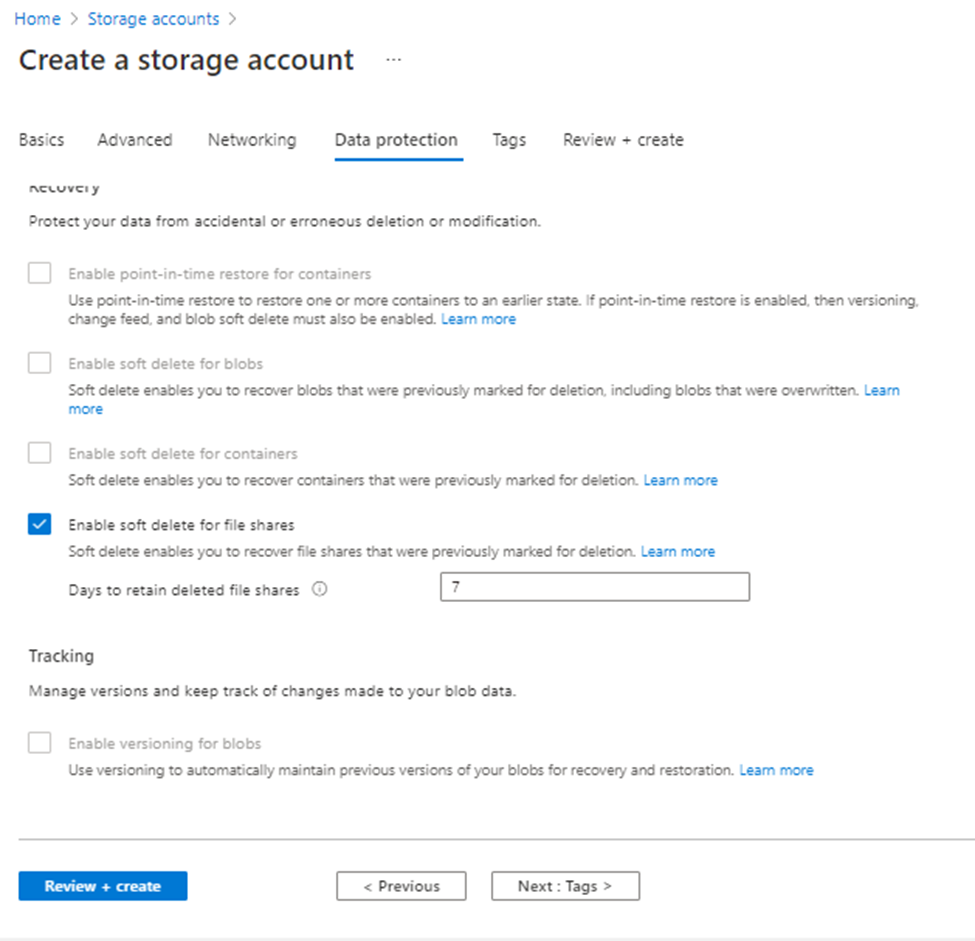
Click Next (Default Options)
Click Next and validate to create
Enable AD DS authentication & Authorization for your Azure file shares -> Onpremises AD DS Authentication
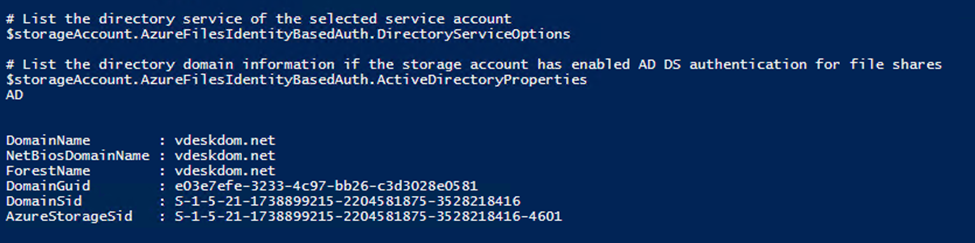
Azure Files supports identity-based authentication over Server Message Block (SMB) through two types of Domain Services: on-premises Active Directory Domain Services (AD DS) and Azure Active Directory Domain Services (Azure AD DS). We strongly recommend you to review the How it works section to select the right domain service for authentication. The setup is different depending on the domain service you choose.
Supported scenarios and restrictions
• AD DS Identities used for Azure Files on-premises AD DS authentication must be synced to Azure AD. Password hash synchronization is optional. • Supports Azure file shares managed by Azure File Sync. • Supports Kerberos authentication with AD with RC4-HMAC and AES 256 encryption. AES 256 encryption support is currently limited to storage accounts with names <= 15 characters in length. AES 128 Kerberos encryption is not yet supported. • Supports single sign-on experience. • Only supported on clients running on OS versions newer than Windows 7 or Windows Server 2008 R2. • Only supported against the AD forest that the storage account is registered to. You can only access Azure file shares with the AD DS credentials from a single forest by default. If you need to access your Azure file share from a different forest, make sure that you have the proper forest trust configured, see the FAQ for details. • Does not support authentication against computer accounts created in AD DS. • Does not support authentication against Network File System (NFS) file shares.
When you enable AD DS for Azure file shares over SMB, your AD DS-joined machines can mount Azure file shares using your existing AD DS credentials. This capability can be enabled with an AD DS environment hosted either in on-prem machines or hosted in Azure.
Prerequisites Before you enable AD DS authentication for Azure file shares, make sure you have completed the following prerequisites:
• Select or create your AD DS environment and sync it to Azure AD with Azure AD Connect.
You can enable the feature on a new or existing on-premises AD DS environment. Identities used for access must be synced to Azure AD. The Azure AD tenant and the file share that you are accessing must be associated with the same subscription.
• Domain-join an on-premises machine or an Azure VM to on-premises AD DS. For information about how to domain-join, refer to Join a Computer to a Domain.
Part one: Enable AD DS authentication for your Azure file shares
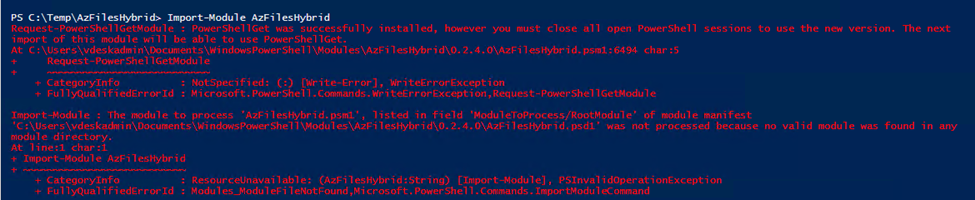
Option 1 (recommended): Use AzFilesHybrid PowerShell module
1.1.1 Download AzFilesHybrid module
• If you don’t have .NET Framework 4.7.2 installed, install it now. It is required for the module to import successfully. • Download and unzip the AzFilesHybrid module (GA module: v0.2.0+) Note that AES 256 kerberos encryption is supported on v0.2.2 or above. If you have enabled the feature with a AzFilesHybrid version below v0.2.2 and want to update to support AES 256 Kerberos encryption, please refer to this article. • Install and execute the module in a device that is domain joined to on-premises AD DS with AD DS credentials that have permissions to create a service logon account or a computer account in the target AD. • Run the script using an on-premises AD DS credential that is synced to your Azure AD. The on-premises AD DS credential must have either Owner or Contributor Azure role on the storage account.
The Join-AzStorageAccountForAuth cmdlet performs the equivalent of an offline domain join on behalf of the specified storage account. The script uses the cmdlet to create a computer account in your AD domain. If for whatever reason you cannot use a computer account, you can alter the script to create a service logon account instead. If you choose to run the command manually, you should select the account best suited for your environment.
The AD DS account created by the cmdlet represents the storage account. If the AD DS account is created under an organizational unit (OU) that enforces password expiration, you must update the password before the maximum password age. Failing to update the account password before that date results in authentication failures when accessing Azure file shares. To learn how to update the password,
Execute below are the steps if Azure Powershell & Azure storage modules not available at client system where you are trying to execute the Join-AzStorageAccountForAuth PowerShell commands
Install-Module Az.Accounts
The problem is that we are unable to install NuGet provider and a couple of errors are showing. Warning unable to download from URI, unable to download the list of available providers. After the errors, it did not install. In this article, you will learn why this is happening and the solution for installing NuGet provider for PowerShell.,
Follow below steps to resolve the above error
First, check the SSL version with below command
Solution for unable to install NuGet provider for PowerShell
Now that we gathered all the information, we are going to enable TLS 1.2 on the system. Run both cmdlets to set .NET Framework strong cryptography registry keys. After that, restart PowerShell and check if the security protocol TLS 1.2 is added
The first cmdlet is to set strong cryptography on 64 bit .Net Framework (version 4 and above).
Steps: .\CopyToPSPath.ps1 Connect-AzAccount (Note: connect the Azure with required credentials ( i.e, account should have permission to access storage and create computer account in domain) Import-Module AzFilesHybrid
Note: Add OrganizationalUnitDistinguishedName if computer account need to join in specific OU
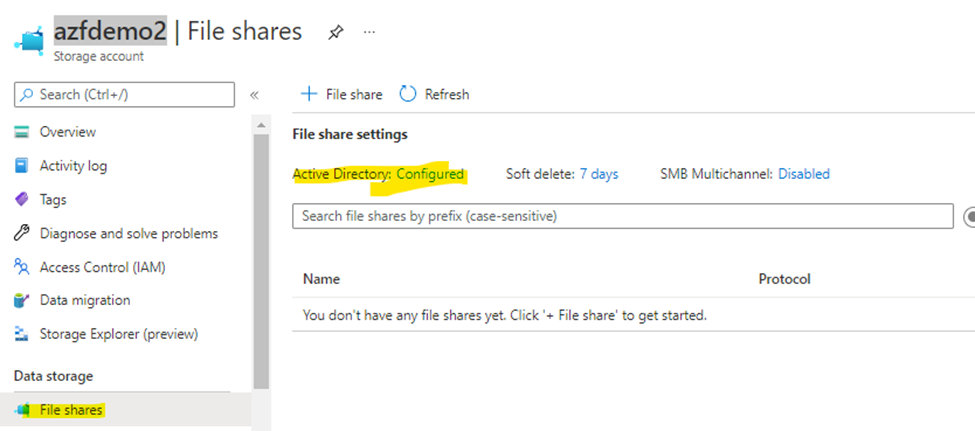
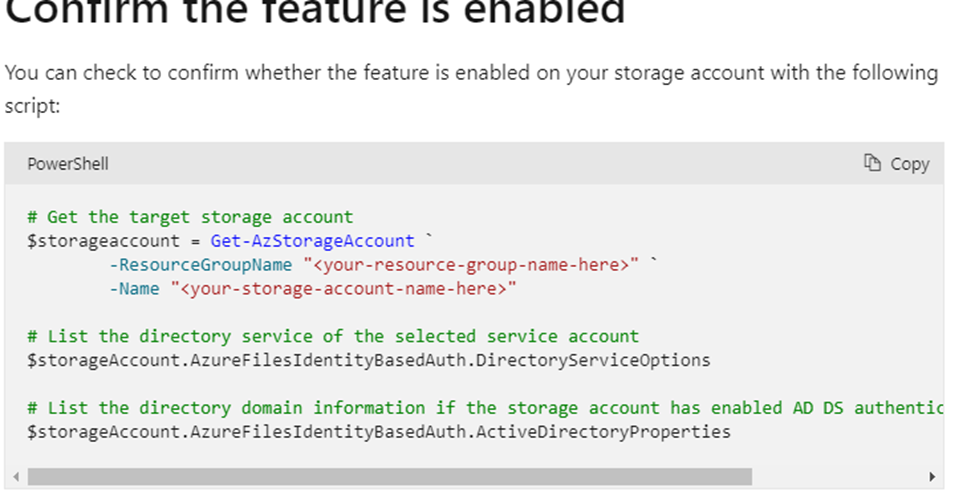
Post execution ->verify from below tools
Or through PowerShell
Note: Update the password of your storage account identity in AD DS
If you registered the Active Directory Domain Services (AD DS) identity/account that represents your storage account in an organizational unit or domain that enforces password expiration time, you must change the password before the maximum password age. Your organization may run automated cleanup scripts that delete accounts once their password expires. Because of this, if you do not change your password before it expires, your account could be deleted, which will cause you to lose access to your Azure file shares.
To trigger password rotation, you can run the Update-
Part 2: Assign share-level permissions to an identity
Once you’ve enabled Active Directory Domain Services (AD DS) authentication on your storage account, you must configure share-level permissions in order to get access to your file shares. There are two ways you can assign share-level permissions. You can assign them to specific Azure AD users/user groups and you can assign them to all authenticated identities as a default share level permission. Share-level permissions for specific Azure AD users or groups Share-level permissions must be assigned to the Azure AD identity representing the same user or group in your AD DS to support AD DS authentication to your Azure file share. Authentication and authorization against identities that only exist in Azure AD, such as Azure Managed Identities (MSIs), are not supported with AD DS authentication.
You can use the Azure portal, Azure PowerShell module, or Azure CLI to assign the built-in roles to the Azure AD identity of a user for granting share-level permissions.
Note: The share level permissions will take upto 3 hours to take effect once completed. Please wait for the permissions to sync before connecting to your file share using your credentials
Share-level permissions for all authenticated identities
You can add a default share-level permission on your storage account, instead of configuring share-level permissions for Azure AD users or groups. A default share-level permission assigned to your storage account applies to all file shares contained in the storage account. When you set a default share-level permission, all authenticated users and groups will have the same permission. Authenticated users or groups are identified as the identity can be authenticated against the on-premises AD DS the storage account is associated with. The default share level permission is set to None at initialization, implying that no access is allowed to files & directories in Azure file share.
Note: You cannot currently assign permissions to the storage account with the Azure portal. Use either the Azure PowerShell module or the Azure CLI, instead.
Mounting prerequisites Before you can mount the file share, make sure you’ve gone through the following pre-requisites:
• If you are mounting the file share from a client that has previously mounted the file share using your storage account key, make sure that you have disconnected the share, removed the persistent credentials of the storage account key, and are currently using AD DS credentials for authentication. For instructions to clear the mounted share with storage account key, refer to FAQ page. • Your client must have line of sight to your AD DS. If your machine or VM is out of the network managed by your AD DS, you will need to enable VPN to reach AD DS for authentication. Replace the placeholder values with your own values, then use the following command to mount the Azure file share. You always need to mount using the path shown below. Using CNAME for file mount is not supported for identity based authentication (AD DS or Azure AD DS).
While volume activation is a process that many have utilized over the years, today’s post offers guidance to help you ensure that all your devices have been properly activated regardless of their connection to your organization’s network.
First, a refresher. Volume activation enables a wide range of Windows devices to receive a volume license and be activated automatically and en masse versus tediously entering an activation key on each Windows device manually.
The most common methods of volume activation require that devices to be connected to an organization’s network or connected via virtual private network (VPN) to “check in” from time to time with the organization’s activation service to maintain their licenses. When people work from home and off the corporate or school network; however, their devices’ ability to receive or maintain activation is limited.
Volume activation methods
There are several methods to activate devices via volume licensing. For detailed information, see Plan for volume activation. Here, however, is a summary for easy reference.
Key Management Service
Key Management Service (KMS) activation requires TCP/IP connectivity to, and accessibility from, an organization’s private network so that licenses are not accessible to anyone outside of the organization. By default, KMS hosts and clients use DNS to publish and find the KMS key. Default settings can be used, which require little or no administrative action, or KMS hosts and client computers can be manually configured based on network configuration and security requirements.
KMS activations are valid for 180 days (the activation validity interval). KMS client computers must renew their activation by connecting to the KMS host at least once every 180 days. By default, KMS client computers attempt to renew their activation every 7 days. If KMS activation fails, the client computer retries to reach the host every two hours. After a client computer’s activation is renewed, the activation validity interval begins again.
Multiple Activation Key
A Multiple Activation Key (MAK) is used for one-time activation with Microsoft’s hosted activation services. Each MAK has a predetermined number of activations allowed. This number is based on volume licensing agreements, and it might not match the organization’s exact license count. Each activation that uses a MAK with the Microsoft-hosted activation service counts toward the activation limit.
You can use a MAK for individual computers or with an image that can be duplicated or installed using Microsoft deployment solutions. You can also use a MAK on a computer that was originally configured to use KMS activation, which is useful for moving a computer off the core network to a disconnected environment.
Active Directory-based activation
Active Directory-based activation is similar to KMS activation but uses Active Directory instead of a separate service. Active Directory-based activation is implemented as a role service that relies on Active Directory Domain Services to store activation objects. Active Directory-based activation requires that the forest schema be updated using adprep.exe on a supported server operating system, but after the schema is updated, older domain controllers can still activate clients.
Devices activated via Active Directory maintain their activated state for up to 180 days after the last contact with the domain. Devices periodically attempt to reactivate (every seven days by default) before the end of that period and, again, at the end of the 180 days.
Windows 10 Subscription Activation
Starting with Windows 10, version 1703 Windows 10 Pro supports the Subscription Activation feature, enabling users to “step-up” from Windows 10 Pro to Windows 10 Enterprise automatically if they are subscribed to Windows 10 Enterprise E3 or E5.
With Windows 10, version 1903 the Subscription Activation feature also supports the ability to step-up from Windows 10 Pro Education to the Enterprise grade edition for educational institutions – Windows 10 Education.
The Subscription Activation feature eliminates the need to manually deploy Windows 10 Enterprise or Education images on each target device, then later standing up on-prem key management services such as KMS or MAK based activation, entering GVLKs, and subsequently rebooting client devices.
To step a device up to Windows 10 Education via Subscription Activation the device must meet the following requirements:
Windows 10 Pro Education, version 1903 or later installed on the devices to be upgraded.
A device with a Windows 10 Pro Education digital license. You can confirm this information in Settings > Update & Security > Activation.
The Education tenant must have an active subscription to Microsoft 365 with a Windows 10 Enterprise license or a Windows 10 Enterprise or Education subscription.
Devices must be Azure AD-joined or Hybrid Azure AD joined. Workgroup-joined or Azure AD registered devices are not supported.
Note: If Windows 10 Pro is converted to Windows 10 Pro Education using benefits available in Store for Education, then the feature will not work. You will need to re-image the device using a Windows 10 Pro Education edition.
Volume activation while working from home
If you activate devices in your organization using MAK, the activation process is straightforward and the devices are permanently activated. If you are using KMS or Active Directory-based Activation, each device must connect to the organization’s local network at least once every 180 days to “check in” with either the KMS host or the Active Directory domain controller. Otherwise, the user will be warned to activate Windows again.
With many users working or taking classes from home, a connection to the organization’s network may not exist, which would ultimately leave their devices in a deactivated state. There are a few options to avoid this:
Use a VPN. By having the device connect to your organization’s network via a VPN, it will be able to contact a KMS host or Active Directory domain controller and will be able to maintain its activation status. If you manage your devices through a wholly on-premises solution to deploy policies, collect inventory, and deploy updates and other software, there is a good chance you are already using a VPN. Depending on the VPN configuration, some manual configuration of the client device may be required to ensure the KMS service is accessible through the VPN. For more details on these settings, which can be implemented via script, see Slmgr.vbs options for obtaining volume activation information.
Convert the devices from KMS to MAK activation. By converting from KMS to MAK activation, you replace the license that requires reactivation every 180 days with a permanent one, which requires no additional check-in process. There are some cases—in educational organizations, for example—where each device is re-imaged at the end of the school year to get ready for the next class. In this case, the license must be “reclaimed” by contacting your Microsoft licensing rep or a Microsoft Licensing Activation Center.
One way of converting a device from KMS to MAK activation is to use the Windows Configuration Designer app (available from the Microsoft Store) to create a provisioning package, which includes the MAK, and deploy the package through email or a management solution such as Microsoft Intune.
You can also deploy a MAK directly within Intune without creating a provisioning package by creating a simple PowerShell script with the following commands and deploying the script to a user group:
slmgr.vbs /ipk XXXXX-XXXXX-XXXXX-XXXXX-XXXXX slmgr.vbs /ato (In the example above, XXXXX-XXXXX-XXXXX-XXXXX-XXXXX is your MAK key.)
It is important to monitor the success of these activations and remove users from the target group once their devices have been activated so that their other devices do not receive a new license.
Use Subscription Activation. This requires the devices to be joined to your Azure AD domain, enabling activation in the cloud. This is possible if you have one of the following subscriptions:
Windows 10 Enterprise E3/E5
Windows 10 Education A3/A5
Windows 10 Enterprise with Software Assurance
Microsoft 365 E3/E5
Microsoft 365 E3/A5
Microsoft 365 F1/F3
Microsoft 365 Business Premium
If you need assistance and have one of the preceding subscriptions with at least 150 licenses, you may be eligible for assistance through FastTrack. Contact your Microsoft representative or request assistance from FastTrack and a Microsoft FastTrack representative will contact you directly.
Conclusion
Windows volume activation has been around for a long time, but the increased number of users working from home may require your organization to re-evaluate how to best keep your devices activated if they cannot reach your on-premises activation service if you are using KMS or Active Directory-based Activation. It is important to consider the options available to you to ensure your devices stay activated. As always, there is no “one-size-fits-all” approach, so consider the pros and cons of each option as you plan on how to best support your remote workers and students.
Below Knowledge base article is published by Dennis Span. This article provides deep dive of understanding & managing of Language packs to build any custom VDI images.