Cluster Shared Volumes (CSV) enable multiple nodes in a failover cluster to simultaneously have read-write access to the same LUN (disk) that is provisioned as an NTFS volume. With CSV, clustered roles can fail over quickly from one node to another node without requiring a change in drive ownership, or dismounting and remounting a volume. CSV also help simplify the management of a potentially large number of LUNs in a failover cluster.
A single CSV can handle hundreds of virtual machines (VMs) and applications—there is no need for a separate logical unit number (LUN) for each VM or application. Each instance of CSV has its own namespace—CSV does not need to use drive letters, making it a more scalable technology than mapped drives
CSV feature introduced firstly in Windows 2008 R2 and significantly enhanced in 2012 (CSV 1.0). Below are the key features in 2012
CSV (v1.0) in Windows Server 2008R2
- First introduced in 2008R2
- CSV v1 only supported the Hyper-V workload and was used to enable Live Migration in Windows Server 2008 R2.
- Implemented as a file system mini-filter
CSV (v2.0) in Windows Server 2012
- In addition to Hyper-v , File services is supported on CSV for application workloads. Can leverage SMB 3.0 and be used for transparent failover Scale-Out File Server (SOFS)
- Improved backup/restore
- Improved performance with block level I/O redirection
- Direct I/O during backup
- CSV works on top of Storage Spaces
- Antivirus and backup filter drivers are now compatible with CSV. Many are already compatible.
- There is a new distributed application consistent backup infrastructure.
- ODX(Offloaded Data Transfer )and spot fixing are supported (Spot-fixing is part of the updated CHKDSK and enables zero downtime for CSV because scanning is done online
- BitLocker is supported on CSV
- Memory mapped I/O works on top of CSV.
- Dependencies on Active Directory Domain Services were removed for improved performance and resiliency.
Windows Server 2012 R2 (CSV 2.0) introduces additional functionality, such as distributed CSV ownership, increased resiliency through availability of the Server service, greater flexibility in the amount of physical memory that you can allocate to CSV cache, better diagnosibility, and enhanced interoperability that includes support for ReFS and deduplication& 2012R2 (CSV 2.0).
CSV provide a general-purpose, clustered file system, which is layered above NTFS (or ReFS in Windows Server 2012 R2). CSV applications include:
- Clustered virtual hard disk (VHD) files for clustered Hyper-V virtual machines
- Scale-out file shares to store application data for the Scale-Out File Server clustered role.
- CSV does not support the Microsoft SQL Server clustered workload in SQL Server 2012 and earlier versions of SQL Server
CSV presents a consistent file namespace (same name ) across all cluster nodes and allows multiple cluster nodes to concurrently access a LUN (Logical Unit Number) on a shared storage system in Microsoft’s Failover Cluster. One of the primary design goals was to support flexible live migration of virtual machines in a Windows Failover Cluster, by providing the facility to host multiple Virtual Machines (VMs) on Clustered Shared Volumes (CSV)
- Eliminates the need for LUN failover in order to failover a VM
- Allows other VM’s on the LUN to exist independent of each other
- Guest VM’s can be moved without requiring any drive ownership changes – Failover without a “Failed State”
- Provides VM complete transparency with respect to which nodes actually own the shared LUN.
Why do we require Cluster Shared Volume (CSV)?
In Windows Server 2008, ownership of disks was determined by a SCSI SPC-3 protocol called ‘Persistent Reservations’ (PRs). When one node “owned” a disk, it would place a reservation on that volume. If another node tried to access this disk, it would ask for ownership of the PR, which would either be granted or denied by the node, which currently owned the reservation. If another node was given ownership of the PR, the physical disk resource would fail over to that node and that node would begin managing access to the LUN.
Since only one node could own the LUN at any time, If any application running on the LUN needed to move to another node, it meant that all applications on that LUN would also be failed over (and have some downtime during that failover).Introduction of Cluster Shared Volumes solves these problems when you are clustering Virtual Machines.
Disk Ownership from 2008R2 with CSV: Clustered Shared Volumes allows nodes to share access to storage, which means that the applications on that piece of storage can run on any node, or on different nodes, at any time. CSV breaks the dependency between application resources (the VMs) and disk resources (for CSV disks) so that in a CSV environment it does not matter where the disk is mounted because it will appear local to all nodes in the cluster. CSV manages storage access differently than regular clustered disks.
CSV gives you the ability to store your VHDs on a single LUN and run the VMs anywhere in the cluster. Additionally, CSV enables Live Migration which allows you to move a running VM from one node to another node with zero downtime. Since disk ownership no longer needs to change when a VM moves to another node, this makes the process quicker and safer, allowing clients to remain connected while the virtual machine is moved to another node in the cluster
In a cluster without CSV, only one node can access a disk LUN at a time, so multiple disks are required for migration. With Cluster Shared Volumes, storage is simplified because multiple nodes can access the same disk at once and fewer overall disks are needed.
A cluster shared volume can be accessed from owner as well non owner node. It can access the disk with direct I/O or through network smb protocol
A CSV typical architecture looks like below.

In the case of CSV, both hosts can see it but only one host owns it and mount the volume over it. The non-owner has the option to send a direct I/O or send it to the coordinator node (owner node) over smb and do the I/O.Generally read and write operations happen over direct I/O and rest of the operations go to coordinator node through NTFS.
Below are the key concepts to dive deep into CSV
Coordinator Node
CSV has the concept of “coordinator” node, “coordinator node typically is the node which owns cluster “Physical Disk” resource of a CSV volume. The one node is synchronizing all access to that volume from all nodes across the cluster.
Non-coordinator (Data Servers) Node
Any other node that does not have clustered disk mounted is called Data Servers (DS)
I/O synchronization
CSV enable multiple nodes to have simultaneous read-write access to the same shared storage. When a node performs, disk input/output (I/O) on a CSV volume, the node communicates directly with the storage, for example, through a storage area network (SAN). However, at any time, a single node (called the coordinator node) “owns” the physical disk resource that is associated with the LUN. The coordinator node for a CSV volume is displayed in Failover Cluster Manager as Owner Node under Disks
CSV enables simultaneous read/write access to the shared LUN from all cluster nodes. Applications can run on any node and can still write to a volume that is only mounted on one of the cluster nodes.
Metadata synchronization is only done on one node (the coordinator node), and metadata changes for all nodes are routed through that coordinator node.
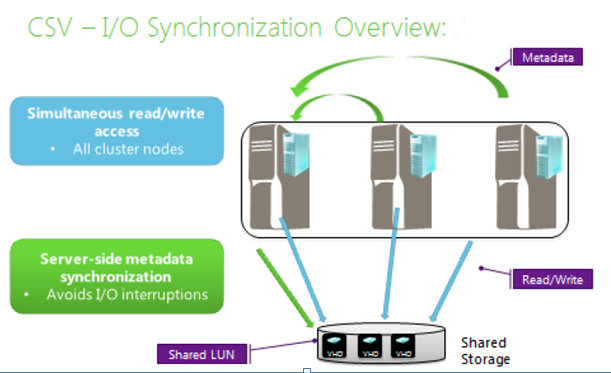
I/O redirection
Storage connectivity failures and certain storage operations can prevent a given node from communicating directly with the storage. To maintain function while the node is not communicating with the storage, the node redirects the disk I/O through a cluster network to the coordinator node where the disk is currently mounted. If the current coordinator node experiences a storage connectivity failure, all disk I/O operations are queued temporarily while a new node is established as a coordinator node.
The server uses one of the following I/O redirection modes, depending on the situation:
- File system redirection Redirection is per volume—for example, when CSV snapshots are taken by a backup application when a CSV volume is manually placed in redirected I/O mode.
- Block redirection Redirection is at the file-block level—for example, when storage connectivity is lost to a volume. Block redirection is significantly faster than file system redirection.
Note:
In Windows Server 2012 R2, you can view the state of a CSV volume on a per node basis. For example, you can see whether I/O is direct or redirected, or whether the CSV volume is unavailable. If a CSV volume is in I/O redirected mode, you can also view the reason.
SMB (Server Message Block) Protocol: It is a network protocol implemented by Microsoft for reading / writing files over the network. For the purpose of CSV, SMB 3.0 multichannel protocol is used. This protocol finds every connection between client (non-owner CSV) and server (owner CSV) host to quickly transfer data. SMB 3.0 includes the SMB Multichannel and SMB Direct features, which enable CSV traffic to stream across multiple networks in the cluster. By default, SMB Multichannel is used for CSV traffic.
CSV Metadata Operations
Metadata updates are lightweight/small operations and only occur in specific situations, including
- VM creation/deletion
- VM power on/off
- VM mobility (live migration or storage live migration)
- Snapshot creation
- Extending a dynamic VHD
- Renaming a VHD
Require redirected I/O. Metadata changes occur in parallel—resulting in faster, non-disruptive operations for applications..
For example,when copying files and CSV is involved, you are talking about MetaData. MetaData is the actual data on the NTFS File system of the CSV drive that you are directly accessing. When Metadata is involved, it is going to go to the “coordinator” node to do the copies.The “coordinator” is the owner as shown in Failover Cluster Manager / Storage / Disks. If you are not sitting on the “coordinator”, then everything is redirected over the network to the node you are sitting on. For example, you are sitting on Node1 and Node2 is the “coordinator“. When you copy something from the CSV to Node1’s local drive, we are going to go over the network to Node2 and copy it back over the network. What you are seeing is a functionality of SMB3 (SMB Multichannel to be precise).
What SMB Multichannel will do is select all the networks that are basically the same (speed, settings, metric, etc) and copy over multiple networks to make things faster than relying on copying over a single network.
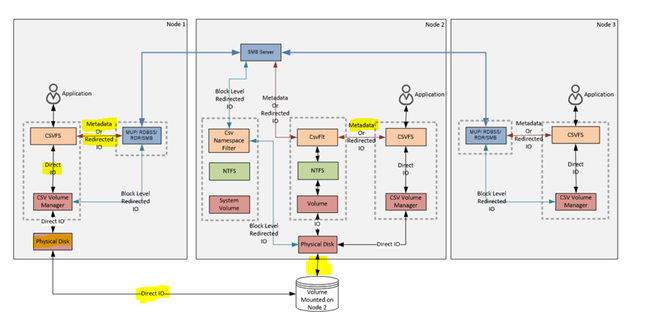
Cluster Shared Volume (CSV) Stack
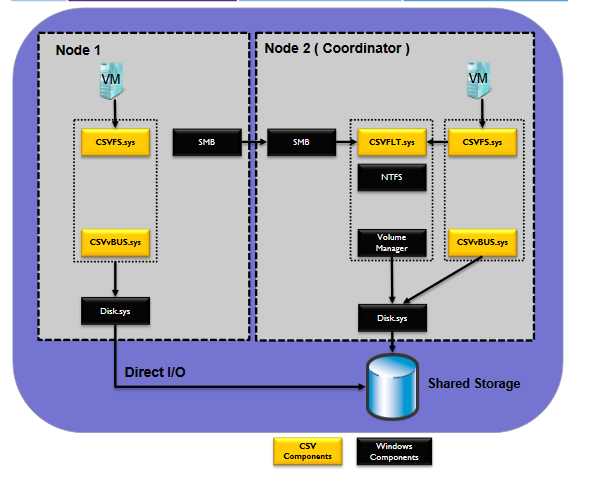
CSV Filter Driver (CSVFLT.sys)
- Mounted on Metadata Coordinator Node
- Blocks access to the NTFS file system
- Co-ordinates metadata operations over SMB
- Filter Altitude – 404800
CSV Proxy File System (CSVFS.sys)
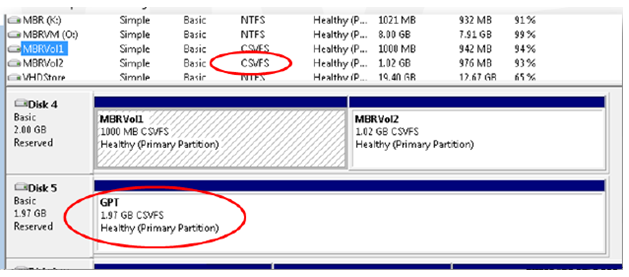
- It is Proxy file system on top of an underlying NTFS file system i. e., CSV volume will be formatted with NTFS but appears as CSVFS instead of NTFS in disk management as shown in below screenshot
- CSV Mounted on every node including Coordinator.
- If the I/O is not metadata i.e., regular read/write I/O — it performs Direct I/O to the physical disk (bypasses the NTFS or ReFS volume stack )à the file system sends the I/O directly down the stack to the storage and provides Direct I/O
- If I/O is metadata only— it performs, Indirect I/O -> i.e., the I/O is routed over the SMB path to the coordinator The coordinator node is the only node where CSV is mounted. For metadata, the NTFS layer handles the changes
- Using CSVFS, applications are aware that a volume is managed by CSV and that it is still NTFS underneath.
CSV Volume Manager (CSVvBUS.sys)
- This driver is the volume manager. This driver makes sure that the csvs are showed as local volumes. This driver sits in the volume layer. If any data parsing is to be performed then it should be done above this driver.
- Responsible for CSV pseudo/virtual volumes
- Block-level IO redirector
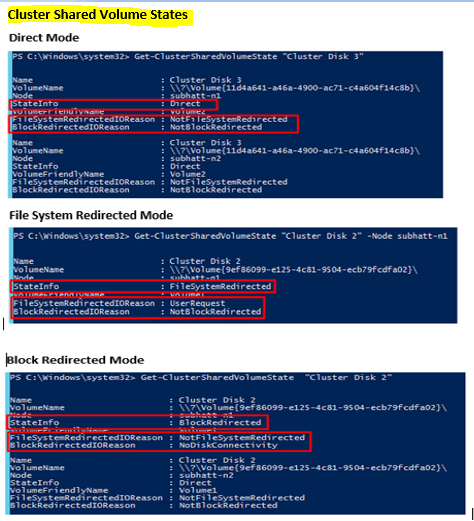
Cluster Shared Volume (CSV) States
The “Get-ClusterSharedVolumeState” cmdlet output provides two important pieces of information for a particular CSV – the state of the CSV and the reason why the CSV is in that particular state. There are three states of a CSV – Direct, File System Redirected and Block Redirected.
Direct Mode
In Direct Mode, I/O operations from the application on the cluster node can be sent directly to the storage. It therefore, bypasses the NTFS or ReFS volume stack
File System Redirected Mode
In File System Redirected mode, I/O on a cluster node is redirected at the top of the CSV pseudo-file system stack over SMB to the disk. This traffic is written to the disk via the NTFS or ReFS file system stack on the coordinator node.
Block Redirected Mode
This is new in WS2012 and provides a much faster redirected IO during storage path failure and redirection. It is still using SMB. Block level redirection goes directly to the storage subsystem and provides 2x disk performance. It bypasses the CSV subsystem on the coordinator node – SMB redirected IO (metadata) must go through this.
In Block level redirected mode, I/O passes through the local CSVFS proxy file system stack and is written directly to Disk.sys on the coordinator node. As a result, it avoids traversing the NTFS/ReFS file system stack twice.
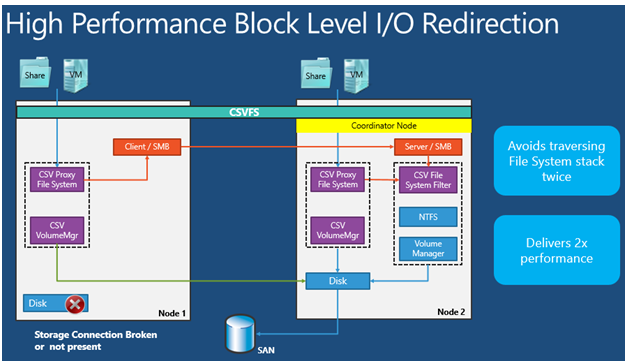
CSV Components and Data Flow Diagram
How does cluster handle Disk Persistent reservation on CSV?
- Add LUN to the host.
- Discover LUN on each of the host of cluster.
- Cluster sends a Persistent reserve <Register and ignore command> to the storage from the host 1 and host 2.
- This command reaches to the multipath driver managing the storage reservations.
- Command goes to the storage where the registration is established.
- Cluster then sends another command Persistent reserve <Reserve command> to establish reservation from host 1 (assuming that this one wants to establish reservation) . This command goes to the storage and if not already reserved, this command is successful.
- Once the reservation is taken then a volume can be mapped out of the CSV and its ready for I/O on each of the host.
How does the CSV handle failures?
Suppose on one of the node I/O fails on the csv then following steps take place.
- All volumes across nodes related to this csv are indicated to start draining.
- All volumes go into a pause.
- Disk will go offline
- Attempt will be made to bring the disk online.
- Registration and reservation will be established to control over the disk.
- Volume will be mounted and and the instance will be attached to csv filter driver.
- CSVFS has about 120 seconds of timeout for volume transition.
Cluster Shared Volume (CSV) Block Cache
Cluster Shared Volumes (CSV) Cache is a feature which allows you to allocate system memory (RAM) as a write-through cache. The CSV Cache provides caching of read-only unbuffered I/O. This can improve performance for applications such as Hyper-V, which conducts unbuffered I/O when accessing a VHD or VHDX file. Unbuffered I/O’s are operations which are not cached by the Windows Cache Manager. What CSV Block Cache delivers is caching which can boost the performance of read requests, with write-through for no caching of write requests.
CSV Cache delivers caching at the block level, which enables it to perform caching of pieces of data being accessed within the VHD file. The primary difference from caching solutions in the form of a PCI card with flash which you add to the server, is that CSV Block Cache reserves its cache from system memory. The CSV Cache also tracks VM mobility and invalidates the cache when it moves from host to host, this removes the need to replicate and keep the cache coherent on all nodes in the cluster. This improves efficiency by not having to cache all VMs on all nodes, as well as reduces the performance overhead of pushing the data between nodes.
CSV Cache is completely integrated into the Failover Clustering feature and handles orchestration across the sets of nodes in the cluster.CSV Cache will deliver the most value in scenarios where VMs are heavy read requests, and are less write intensive. Scenarios such as Pooled VDI VMs or also for reducing VM boot storms.
- Hyper-V – In preliminary testing, it has found 512 MB to deliver excellent gain at minimal cost, and is the recommend starting point / minimal value if enabled. Then based on your specific deployment and the I/O characteristics of the workloads in the VMs you may wish to increase the amount of memory allocated. Since system, memory is a contended resource on a Hyper-V cluster, it is recommended to keep the CSV Cache size moderate. Such as 512 MB, 1 GB, or 2 GB
- Scale-out File Server – It is recommended to allocate a significantly larger CSV Cache on a SoFS as physical memory is typically not a contended resource, you may want to allocate 4 GB, 6 GB, or even more…
There are two configuration settings that allow you to control CSV Cache.
- BlockCacheSize – This is a cluster common property that allows you to define how much memory (in megabytes) you wish to reserve for the CSV Cache on each node in the cluster. If a value of 512 is defined, then 512 MB of system memory will be reserved on each node in the Failover Cluster. Configuring a value of 0 disables CSV Block Cache.
- EnableBlockCache – This is a private property of the cluster Physical Disk resource. It allows you to enable/disable caching on an individual disk. This gives the flexibility to configure cache for read intensive VMs running on some disks, while allowing to disable and prevent random I/O on other disks from purging the cache. For example parent VHD’s with high reads you would enable caching on Disk1, and high writes for differencing disks the CSV cache could be disabled on Disk2. The default setting is 1 for enabled.
CSV cache is disabled by default in 2012 whereas it enabled in Server 2012 R2, the CSV cache is enabled by default. However, you must still allocate the size of the block cache to reserve
This has a very high value for pooled VDI VM scenario. Read-only (differencing) parent VHD or read-write differencing VHDs.
To Enable Cache at cluster level -> (Get-Cluster). BlockCacheSize = 1024
Once the CSV Cache is enabled, all disks on all nodes will be cached by default. You have the flexibility to disable the CSV Cache on an individual disk using the following process:
Get-ClusterSharedVolume “Cluster Disk 1” | Set ClusterParameter EnableBlockCache 0
CSV Cache Considerations
Windows Server 2012
- Maximum of 20% of the total physical RAM can be allocated for the CSV write-through cache with Windows Server 2012
- The cache size can be modified with no downtime, however for the Hyper-V root memory reserve in the parent partition to be modified to accommodate the memory allocated to the CSV cache it does require a server reboot with Windows Server 2012. To ensure resource contention is avoided, it is recommended to reboot each node in the cluster after modifying the memory allocated to the CSV cache.
- Enabling CSV Cache on an individual disk requires that the Physical Disk resource be recycled (taken Offline / Online) for it to take effect. This can be done with no downtime by simply moving ownership of the Physical Disk resource from one node to another.
- The EnableBlockCache private property is named CsvEnableBlockCache in Windows Server 2012
- The BlockCacheSize common property is named SharedVolumeBlockCacheSizeInMB in Windows Server 2012
- The way it is enabled is also slightly different, here is the process:
Define the size of the size of the cache to be reserved (example of setting to 1 GB)
(Get-Cluster). SharedVolumeBlockCacheSizeInMB = 1024
Enable CSV Cache on an individual disk (must be executed for every disk you wish to enable caching)
Get-ClusterSharedVolume “Cluster Disk 1” | Set-ClusterParameter CsvEnableBlockCache 1
Windows Server 2012 R2:
- Enabling CSV Cache on an individual disk requires that the Physical Disk resource be recycled (taken Offline / Online) for it to take effect. This can be done with no downtime by simply moving ownership of the Physical Disk resource from one node to another.
- Recommended not to exceed allocating 64 GB on Windows Server 2012 R2
- CSV Cache will be disabled on:
- Tiered Storage Space with heat map tracking enabled
- Deduplicated files using in-box Windows Server Data Deduplication feature (Note: Data will instead be cached by the dedup cache)
- ReFS volume when integrity streams is enabled
Cluster Shared Volume Backup
CSV 2.0 has introduced a groundbreaking feature named “Distributed application consistent backup” in a Windows Failover cluster. This allows the customers to backup all the VMs in a cluster to be consistent in one application consistent backup.
Microsoft has introduced two new components in the VSS framework supporting the CSV 2.0 application consistent backup. A new “CSV Writer” and “CSV Provider” have been added into the WS 2012 to achieve the distributed backup. CSV Writer serves the Component level metadata from non-requesting node for CSV volumes and act as a proxy by including the Hyper-V writers from remote node for the backup session. In addition, the metadata of the Virtual machines reported by the CSV writer defers comparing to the Hyper-V writer. This puts extra work on the requestors to understand the component schema and do the necessary backup preparation mechanisms.
CSV Provider co-ordinates the VSS Freeze and Thaw from all the Hyper-V writers on the partner cluster nodes to make the VM in an application consistent state. In addition, the CSV provider makes sure that CSV shadow copy volume is writable for the partner node Hyper-V writers during the auto recovery process explained earlier.
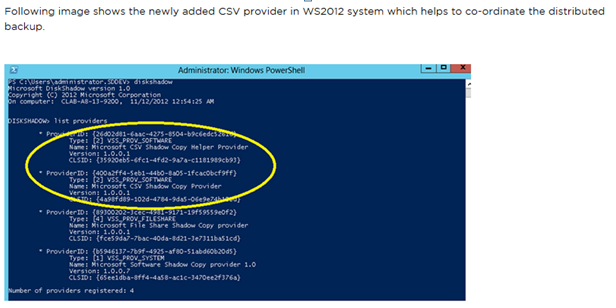
There are multiple methods to back up information that is stored on CSV in a failover cluster. You can use a Microsoft backup application or a non-Microsoft application.
Windows Server Backup generally provides only a basic backup solution that may not be suited for organizations with larger clusters. Windows Server Backup does not support application-consistent virtual machine backup on CSV. It supports crash-consistent volume-level backup only.
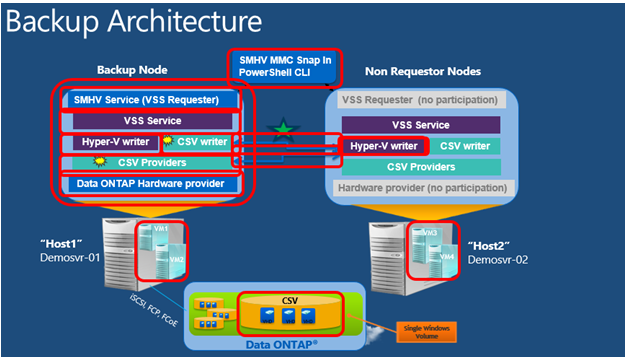
CSV writer queries all the partner node VM metadata for the VSS requestor on the backup node. The VSS hardware provider is only contacted on the backup node and finally only one hardware snapshot is created for the entire CSV volume. Below is typical steps for a CSV backup
- Backup application talks to the VSS Service on the backup node
- The Hyper-V writer identifies the local VMs on the backup node
- Backup node CSV writer contacts the Hyper-V writer on the other hosts in cluster to gather metadata of files being used by VMs on that CSV
- CSV Provider on backup node contacts Hyper-V Writer to get quiesce the VMs
- Hyper-V Writer on the backup node also quiesces its own VMs
- VSS snapshot of the entire CSV is created
- The backup tool can then backup the CSV via the VSS snapshot
Designating a Preferred Network for Cluster Shared Volumes Communication
When you enable Cluster Shared Volumes, the failover cluster automatically chooses the network that appears to be the best for CSV communication. However, you can designate the network by using the cluster network property, Metric. The lowest Metric value designates the network for CSV and internal cluster communication. The second lowest value designates the network for live migration, if live migration is used (you can also designate the network for live migration by using the failover cluster snap-in).
Get-ClusterNetwork | ft Name, Metric, AutoMetric, Role
To change the Metric setting to 900 for the network named Cluster Network 1, type the following:
( Get-ClusterNetwork “Cluster Network 1” ).Metric = 900
Note: CSV uses the Private Network communication. You can designate Network’s from failover cluster Network properties -> Recommend to have two Private Networks, one for Private and another for CSV
Failover Console ->Cluster Network -> Settings ->Allow Cluster Communications on Network and Uncheck “Clear all the Allow Clients to connect through this network” setting
Common CSV Event Errors (Troubleshooting):
Each Cluster node will have direct access to a CSV LUN as well as redirected access over the network.
Event Id 5120 or 5142 –> 5120 errors indicate a failure of redirected I/O, and a 5142 indicates a failure of both redirected and direct
Event Id 5142 indicates that the non-owning node is disconnected and CSV is no longer queuing the I/O. As a result, the VM’s on the node logging the errors will see the storage as disconnected instead of just slow in responding.
Event Id 129
Warning events are logged to the system event log with the storage adapter (HBA) driver’s name as the Source. Windows’ STORPORT.SYS driver logs this message when it detects that a request has timed out, the HBA driver’s name is used in the error because it is the miniport associated with storport
The most common causes of the Event ID 129 errors are unresponsive LUNs or a dropped request. Faulty routers or other hardware problems on the SAN can cause dropped requests. If you are seeing Event ID 129 errors in your event logs, then you should start investigating the storage and fibre network
Event Id 153
An event 153 is similar to an event 129. An event 129 is logged when the storport driver times out a request to the disk. The difference between a 153 and a 129 is that a 129 is logged when storport times out a request, a 153 is logged when the storport miniport driver times out a request.
The miniport driver may also be referred to as an adapter driver or HBA driver, this driver is typically written the hardware vendor.
Event id 5217 -> Events logged if Backup Snapshot errors
Event id 5150 -> Events logged if CSV put in failed state
Additional References
Cluster Shared Volume (CSV) Inside Out
http://blogs.msdn.com/b/clustering/archive/2013/12/02/10473247.aspx
Cluster Shared Volume Diagnostics
http://blogs.msdn.com/b/clustering/archive/2014/03/13/10507826.aspx
Cluster Shared Volume Performance Counters
http://blogs.msdn.com/b/clustering/archive/2014/06/05/10531462.aspx
Cluster Shared Volume Failure Handling
http://blogs.msdn.com/b/clustering/archive/2014/10/27/10567706.aspx
Troubleshooting Cluster Shared Volume Auto-Pauses – Event 5120
http://blogs.msdn.com/b/clustering/archive/2014/12/08/10579131.aspx
Troubleshooting Cluster Shared Volume Recovery Failure – System Event 5142
http://blogs.msdn.com/b/clustering/archive/2015/03/26/10603160.aspx
Use Cluster Shared Volumes in a Failover Cluster
https://technet.microsoft.com/en-us/library/jj612868(v=ws.11).aspx
Category: Cluster Shared Volumes
https://blogs.msdn.microsoft.com/clustering/category/cluster-shared-volumes/
How to Enable CSV Cache
https://blogs.msdn.microsoft.com/clustering/2013/07/19/how-to-enable-csv-cache/
Cluster Shared Volume – A Systematic Approach to Finding Bottlenecks
Understanding the state of your Cluster Shared Volumes
The Windows Disk timeout value: Less is better
https://blogs.msdn.microsoft.com/san/2011/09/01/the-windows-disk-timeout-value-less-is-better/
Cluster Shared Volumes (CSV): Disk Ownership
https://blogs.msdn.microsoft.com/clustering/2009/03/01/cluster-shared-volumes-csv-disk-ownership/