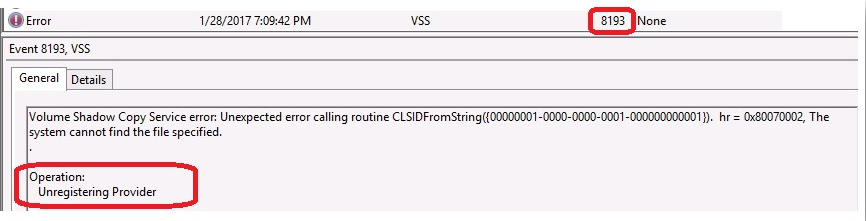
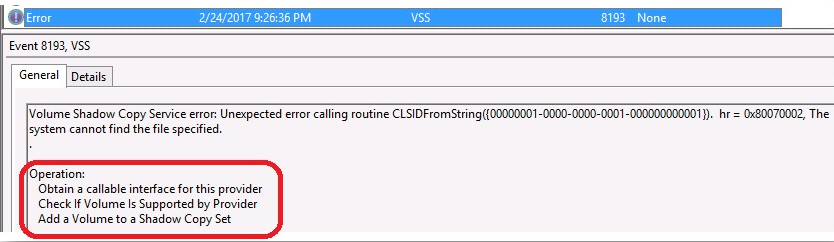
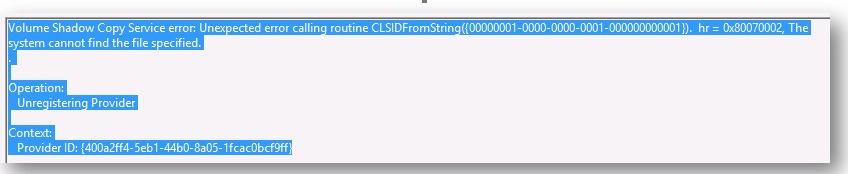
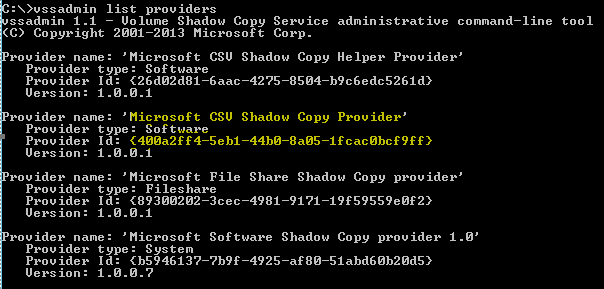
Hyper-V integration services, are a bundled set of software which, when installed in the virtual machine improves integration between the host server and the virtual machine. Integration services (often called integration components), are services that allow the virtual machine to communicate with the Hyper-V host. Hyper-V Integration Services is a suite of utilities in Microsoft Hyper-V, designed to enhance the performance of a virtual machine’s guest operating system.
In short and general, the integration services are a set of drivers so that the virtual machine can make use of the synthetic devices provisioned to the VM by Hyper-V.
Hyper-V Integration Services optimizes the drivers of the virtual environments to provide end users with the best possible user experience. The suite improves virtual machine management by replacing generic operating system driver files for the mouse, keyboard, video, network and SCSI controller components. It also synchronizes time between the guests and host operating systems and can provide file interoperability and a heartbeat.
Below is the list of Integration Services Version numbers
Windows Server 2008
| Build Number | Knowledge Base Article ID | Comment |
| 6.0.6001.17101 | n/a | Windows Server 2008 RTM |
| 6.0.6001.18016 | KB950050 | Windows Server 2008 RTM + KB950050 |
| 6.0.6001.22258 | KB956710 | Windows Server 2008 RTM + KB956710 |
| 6.0.6001.22352 | KB959962 | Windows Server 2008 RTM + KB959962 |
| 6.0.6002.18005 | KB948465 | Windows Server 2008 Service Pack 2 |
| 6.0.6002.22233 | KB975925 | Windows Server 2008 RTM + KB975925 |
Windows Server 2008 R2
| Build Number | Knowledge Base Article ID | Comment |
| 6.1.7600.16385 | n/a | Windows Server 2008 R2 RTM |
| 6.1.7600.20542 | KB975354 | Windows Server 2008 R2 RTM + KB975354 |
| 6.1.7600.20683 | KB981836 | Windows Server 2008 R2 RTM + KB981836 |
| 6.1.7600.20778 | KB2223005 | Windows Server 2008 R2 RTM + KB2223005 |
| 6.1.7601.16562 | n/a | Windows Server 2008 R2 Service Pack 1 Beta |
| 6.1.7601.17105 | n/a | Windows Server 2008 R2 Service Pack 1 RC |
| 6.1.7601.17514 | KB976932 | Windows Server 2008 R2 Service Pack 1 RTM |
Windows Server 2012
| Build Number | Knowledge Base Article ID | Comment |
| 6.2.9200.16384 | n/a | Windows Server 2012 RTM |
| 6.2.9200.16433 | KB2770917 | Windows Server 2012 RTM + KB2770917 |
| 6.2.9200.20655 | KB2823956 | Windows Server 2012 RTM + KB2823956 |
| 6.2.9200.21885 | KB3161609 | June 2016 update rollup for Windows Server 2012 |
Windows Server 2012 R2
| Build Number | Knowledge Base Article ID | Comment |
| 6.3.9600.16384 | n/a | Windows Server 2012 R2 RTM |
| 6.3.9600.17415 | Windows Server 2012 R2 RTM + KB3000850 | |
| 6.3.9600.17831 | KB3063283 | Windows Server 2012 R2 RTM + KB3063283 |
| 6.3.9600.18080 | KB3063109 | Windows Server 2012 R2 RTM + KB3063109 |
| 6.3.9600.18339 | KB3161606 | June 2016 update rollup for Windows Server 2012 R2 |
| 6.3.9600.18398 | KB3172614 | July 2016 update rollup for Windows Server 2012 R2 |
| 6.3.9600.18692 | June 27, 2017—KB4022720 (Preview of Monthly Rollup) |