Immediate Observations:
-
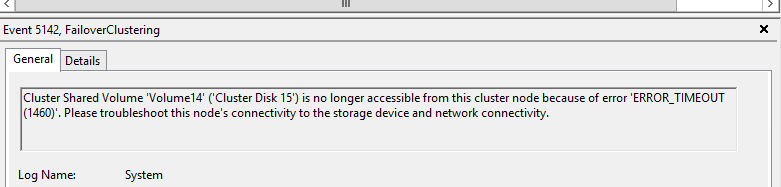
During network core switch activity, there was a network disturbance for both public & private network interfaces for 30 to 60 sec’s and it is fluctuated in duration of 2 hours
-
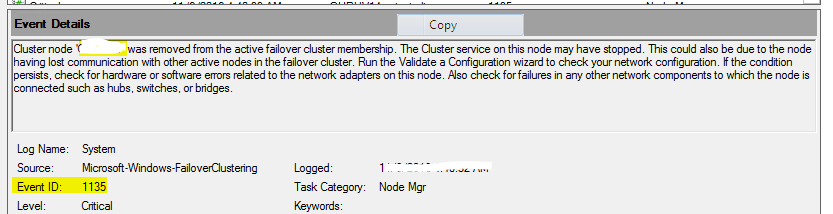
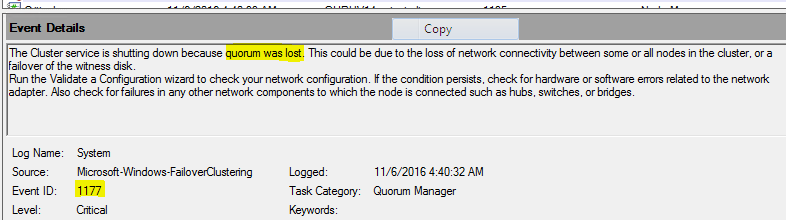
Observed the event id’s 1127(network fail),1135(Removal of cluster membership),1177(quorum lost) & 5120(CSV disconnection)


Immediate Action’s performed
- As heartbeat is not available & other interface not interrupting , we have increased the heartbeat value by increasing the Same Subnet Threshold from default 5 sec to 28 Sec. This value is kept by referring the below blog
- As per Microsoft recommendation we should not have samesubnetthreshold value > 20 sec. Since we observed VLAN flapping is taking 25 sec, we have set the value to 28 to check , we have changed samesubnetThreshold to 28 which is heartbeat value. However we can’t set routehistorylength value more than 40 due to limitation.
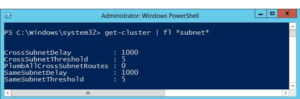
So, By default total heart beat in a cluster is = Delay * Threshold = 1 sec * 5 HB i.e. cluster can tolerate of 5 HB in 5 sec
Threshold – This defines the number of heartbeats which are missed before the cluster takes recovery action
For example setting SameSubnetDelay to send a heartbeat every 2 seconds and setting the SameSubnetThreshold to 10 heartbeats missed before taking recovery, means that the cluster can have a total network tolerance of 20 seconds(2sec *10 HB) before recovery action is taken

Changing of above 28 HB’s would not help us our requirement as network fluctuations are more than 30 sec hence we have sought Microsoft support for any other best practice and got below recommendations
- The samesubnedelay and samesubnetthreashold values are very specific to heartbeat settings between cluster nodes/hosts. These changes will help delay the heartbeat checks between the nodes/hosts.
- The above changes will not control the way the SMB multi-channel that is used by the Cluster Shared Volumes (CSV). The moment the TCP connection is dropped during the network maintenance activity, the SMB channel will have an impact.
- As the SMB connection drops, it will affect the VMs hosted on the CSV volumes. They will not be able to get the metadata for the CSV over the SMB channel.
- Due to problems over CSV network (SMB channel), you would see event ID 5120 for CSV volumes. This will impact the VM availability.
So based on the above points, if there is a network outage beyond 10-20 seconds, there will be impact to the cluster and there is no way to avoid this impact on the VM resources. It is recommended to ensure the VMs are moved to the nodes where will be no network impact or to be brought offline gracefully before the network maintenance activity.
Also, MS responded as below for the query which we asked to check and it may not viable in CSV environment as SMB connection drops impacting CSV
Removal and adding of the VM from HA is time consuming and not an easy option and Microsoft do not suggest this option in CSV environment.
Ref: https://blogs.msdn.microsoft.com/clustering/2012/11/21/tuning-failover-cluster-network-thresholds/