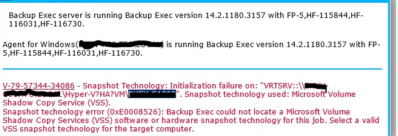
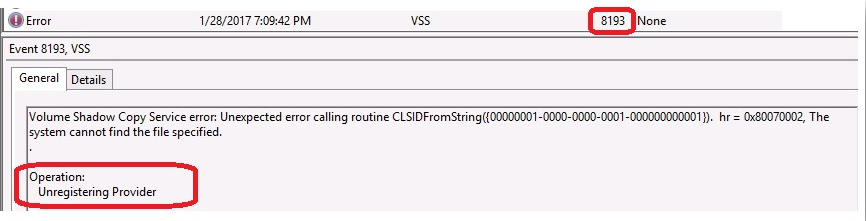
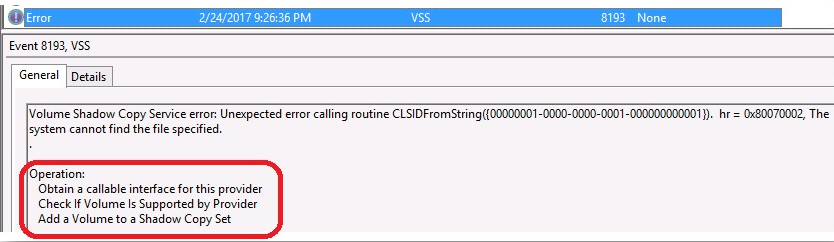
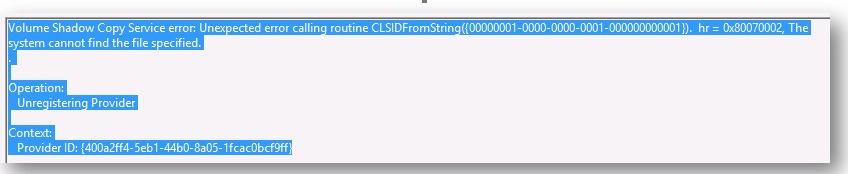
Issue:
In one of our customer infra, for one of the VM ,snapshot grown to 1.9 TB size and it was created by one of the engineer as part of IS upgradation but forgot to delete.
Environment
- Hyper-v : 2012R2 cluster (4 Nodes)
- 2 Volumes (Volume1 – 7 TB (Free space 1.18 TB), Volume2 -7 TB (980 GB free space) )
- VM Role: Standalone critical VM where MS SQL(2008R2) databases are hosted and the size of all databases(100) is 1.3 TB.
Challenges:
- VM level backups are not existed due to backup license issue , however regular database backup is happening with backup tool . But, as on date SQL & backup team not tested restoration.
- Expected additional free space from storage as snapshot deletion activity requires equivalent VHD free space -> Due to storage credentials issue, storage team unable to provide any support.
Due to above 2 challenges, planned below options and completed as part of prerequisites
- Removed all unwanted files from Volume2 and made the free space of 1.6 TB in Volume2 so that while snapshot deletion(merging) it should not have space issue
- Built new VM(SQL Server) and do database restoration to new SQL server -> This test is to estimate the restoration time and check database consistency
Implementation plan:
Prerequisites
- As there is no VM level backup, backup team need to take FULL database backup & differential backup post downtime
- Shutdown VM
- Move CSV’s Volume 1 & 2 to the Hyper-v Server where VM hosted -> To provide better I/O
- Make sure only one VM is hosted on Hyper-v Server -> To provide better performance and we have sufficient resource to have only one VM
Implementation Plan:
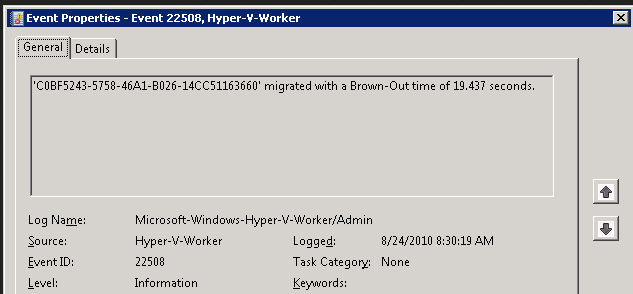
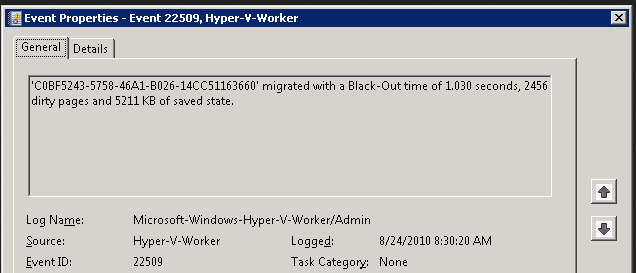
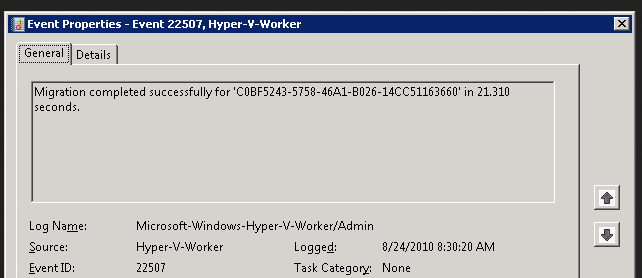
- Go To Hyper-V Manager -> Select VM -> Right Click ->Delete Snapshot
Note: If Merge process taking more than expected, we cannot can cancel in between the merge process as there are lot of chance corruption
Roll Back Plan:
- Backup team need to restore SQL databases directly to new VM which was prepared as Standby
- Change the Hostname & IP to production
- SQL team need to change the hostname at SQL Instance level
- Application team need to check the connectivity
| Before Execution | Post Snapshot Deletion VM File Size |
||||||
| VHD File | Drives letters in OS | Parent File | Snapshot File | Total VM | Storage Volume | ||
| Drive0.VHDX | C | 83.3 | 46.8 | 130.1 | 87.2 | Volume 1 | |
| Drive1.VHDX | E | 1540 | 437.7 | 1977.7 | 1540 | Volume 1 | |
| Drive3.VHDX | F | 221.6 | 214.8 | 436.4 | 271.2 | Volume 1 | |
| Drive4.vhdx | G | 1950 | 1240 | 3190 | 1950 | Volume 2 | |
| 3794.9 | 1939.3 | 5734.2 | 3848.4 | ||||
| Time taken for Deletion of Snapshot 1.9 TB in Offline is 5 hrs. (12:30 to 5:30 A.M), space reclaimed is 1885.8 GB | |||||||