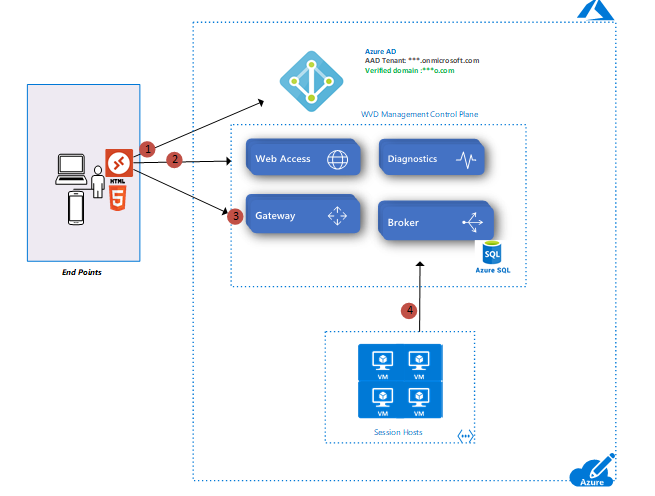
Below are the common WVD build issues which I encountered during implementations
Issue 1 -Unable to create any Host Pool
Error
{“code”:”DeploymentFailed”,”message”:”At least one resource deployment operation failed. Please list deployment operations for details. Please see https://aka.ms/DeployOperations for usage details.”,”details”:[{“code”:”Conflict”,”message”:”{\r\n \”status\”: \”Failed\”,\r\n \”error\”: {\r\n \”code\”: \”ResourceDeploymentFailure\”,\r\n \”message\”: \”The resource operation completed with terminal provisioning state ‘Failed’.\”,\r\n \”details\”: [\r\n {\r\n \”code\”: \”DeploymentFailed\”,\r\n \”message\”: \”At least one resource deployment operation failed. Please list deployment operations for details. Please see https://aka.ms/DeployOperations for usage details.\”,\r\n \”details\”: [\r\n {\r\n \”code\”: \”Conflict\”,\r\n \”message\”: \”{\r\n \\”status\\”: \\”Failed\\”,\r\n \\”error\\”: {\r\n \\”code\\”: \\”ResourceDeploymentFailure\\”,\r\n \\”message\\”: \\”The resource operation completed with terminal provisioning state ‘Failed’.\\”,\r\n \\”details\\”: [\r\n {\r\n \\”code\\”: \\”VMExtensionProvisioningError\\”,\r\n \\”message\\”: \\”VM has reported a failure when processing extension ‘dscextension’. Error message: \\\\”The DSC Extension failed to execute: Error downloading https://wvdportalstorageblob.blob.core.windows.net/galleryartifacts/Configuration_9-11-2020.zip after 29 attempts: Unable to connect to the remote server.\\r\\nMore information about the failure can be found in the logs located under ‘C:\\\\WindowsAzure\\\\Logs\\\\Plugins\\\\Microsoft.Powershell.DSC\\\\2.80.1.0’ on the VM.\\\\”\\r\\n\\r\\nMore information on troubleshooting is available at https://aka.ms/VMExtensionDSCWindowsTroubleshoot \\”\r\n }\r\n ]\r\n }\r\n}\”\r\n },\r\n {\r\n \”code\”: \”Conflict\”,\r\n \”message\”: \”{\r\n \\”status\\”: \\”Failed\\”,\r\n \\”error\\”: {\r\n \\”code\\”: \\”ResourceDeploymentFailure\\”,\r\n \\”message\\”: \\”The resource operation completed with terminal provisioning state ‘Failed’.\\”,\r\n \\”details\\”: [\r\n {\r\n \\”code\\”: \\”VMExtensionProvisioningError\\”,\r\n \\”message\\”: \\”VM has reported a failure when processing extension ‘dscextension’. Error message: \\\\”The DSC Extension failed to execute: Error downloading https://wvdportalstorageblob.blob.core.windows.net/galleryartifacts/Configuration_9-11-2020.zip after 29 attempts: Unable to connect to the remote server.\\r\\nMore information about the failure can be found in the logs located under ‘C:\\\\WindowsAzure\\\\Logs\\\\Plugins\\\\Microsoft.Powershell.DSC\\\\2.80.1.0’ on the VM.\\\\”\\r\\n\\r\\nMore information on troubleshooting is available at https://aka.ms/VMExtensionDSCWindowsTroubleshoot \\”\r\n }\r\n ]\r\n }\r\n}\”\r\n }\r\n ]\r\n }\r\n ]\r\n }\r\n}”}]}
Root Cause:
There was no internet access for the subnet used for host pool creation
Resolution:
Internet connectivity required for WVD VNET as DSC extension need to download from Azure Websites. The DSC extension for Windows requires that the target virtual machine is able to communicate with Azure and the location of the configuration package (.zip file) if it is stored in a location outside of Azure.
Ref: https://docs.microsoft.com/en-us/azure/virtual-machines/extensions/dsc-windows
Issue 2: Unable to create Host pool from Custom Image
Error
{“code”:”DeploymentFailed”,”message”:”At least one resource deployment operation failed. Please list deployment operations for details. Please see https://aka.ms/DeployOperations for usage details.”,”details”:[{“code”:”Conflict”,”message”:”{\r\n \”status\”: \”Failed\”,\r\n \”error\”: {\r\n \”code\”: \”ResourceDeploymentFailure\”,\r\n \”message\”: \”The resource operation completed with terminal provisioning state ‘Failed’.\”,\r\n \”details\”: [\r\n {\r\n \”code\”: \”DeploymentFailed\”,\r\n \”message\”: \”At least one resource deployment operation failed. Please list deployment operations for details. Please see https://aka.ms/DeployOperations for usage details.\”,\r\n \”details\”: [\r\n {\r\n \”code\”: \”Conflict\”,\r\n \”message\”: \”{\r\n \\”status\\”: \\”Failed\\”,\r\n \\”error\\”: {\r\n \\”code\\”: \\”ResourceDeploymentFailure\\”,\r\n \\”message\\”: \\”The resource operation completed with terminal provisioning state ‘Failed’.\\”,\r\n \\”details\\”: [\r\n {\r\n \\”code\\”: \\”VMExtensionProvisioningTimeout\\”,\r\n \\”message\\”: \\”Provisioning of VM extension dscextension has timed out. Extension provisioning has taken too long to complete. The extension did not report a message. More information on troubleshooting is available at https://aka.ms/VMExtensionDSCWindowsTroubleshoot\\”\r\n }\r\n ]\r\n }\r\n}\”\r\n },\r\n {\r\n \”code\”: \”Conflict\”,\r\n \”message\”: \”{\r\n \\”status\\”: \\”Failed\\”,\r\n \\”error\\”: {\r\n \\”code\\”: \\”ResourceDeploymentFailure\\”,\r\n \\”message\\”: \\”The resource operation completed with terminal provisioning state ‘Failed’.\\”,\r\n \\”details\\”: [\r\n {\r\n \\”code\\”: \\”VMExtensionProvisioningTimeout\\”,\r\n \\”message\\”: \\”Provisioning of VM extension dscextension has timed out. Extension provisioning has taken too long to complete. The extension did not report a message. More information on troubleshooting is available at https://aka.ms/VMExtensionDSCWindowsTroubleshoot\\”\r\n }\r\n ]\r\n }\r\n}\”\r\n }\r\n ]\r\n }\r\n ]\r\n }\r\n}”}]
Root Cause
Issue with Image which is captured from existing Host Pool
Resolution
Do not capture image from Hostpool Sessions as this breaks sometimes , always
Take new image from Market Place ->convert to Image ->Create Host pools -> For Host update , again use previous captured image
Issue 3: Host pools are able to create with fresh images but not with applications installed on Image (custom)
Error
{“code”:”DeploymentFailed”,”message”:”At least one resource deployment operation failed. Please list deployment operations for details. Please see https://aka.ms/DeployOperations for usage details.”,”details”:[{“code”:”VMExtensionProvisioningTimeout”,”message”:”Provisioning of VM extension joindomain has timed out. Extension provisioning has taken too long to complete. The extension did not report a message. More information on troubleshooting is available at https://aka.ms/vmextensionwindowstroubleshoot”}]}
Root Cause
Visual studio 2015 & 2017 , customer 3rd part application are blocking to create Host pool – Issue experienced with 2 customers
Resolution
Able to create Hostpools after uninstallation of Visual studio