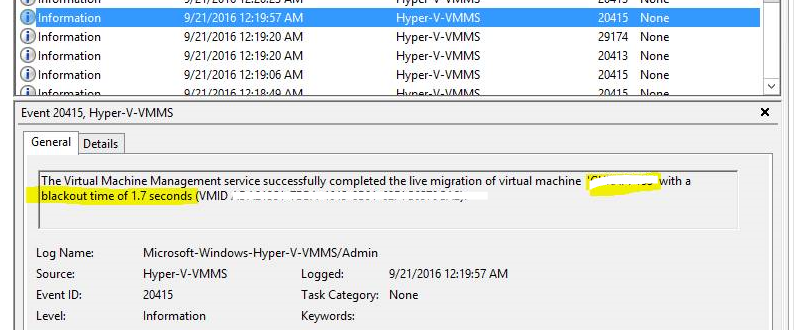
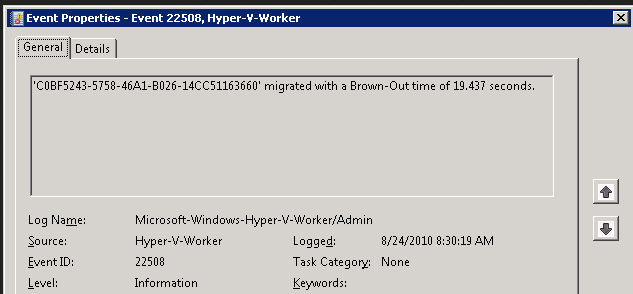
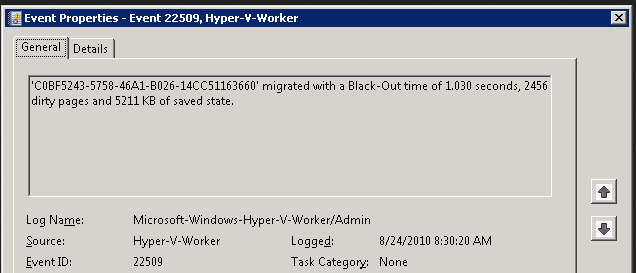
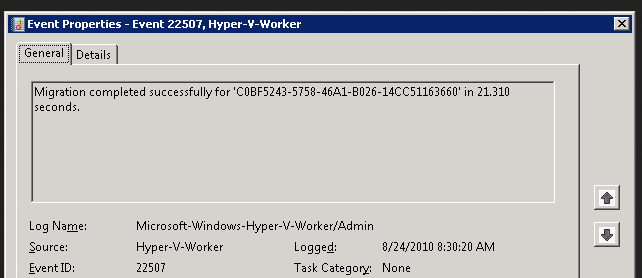
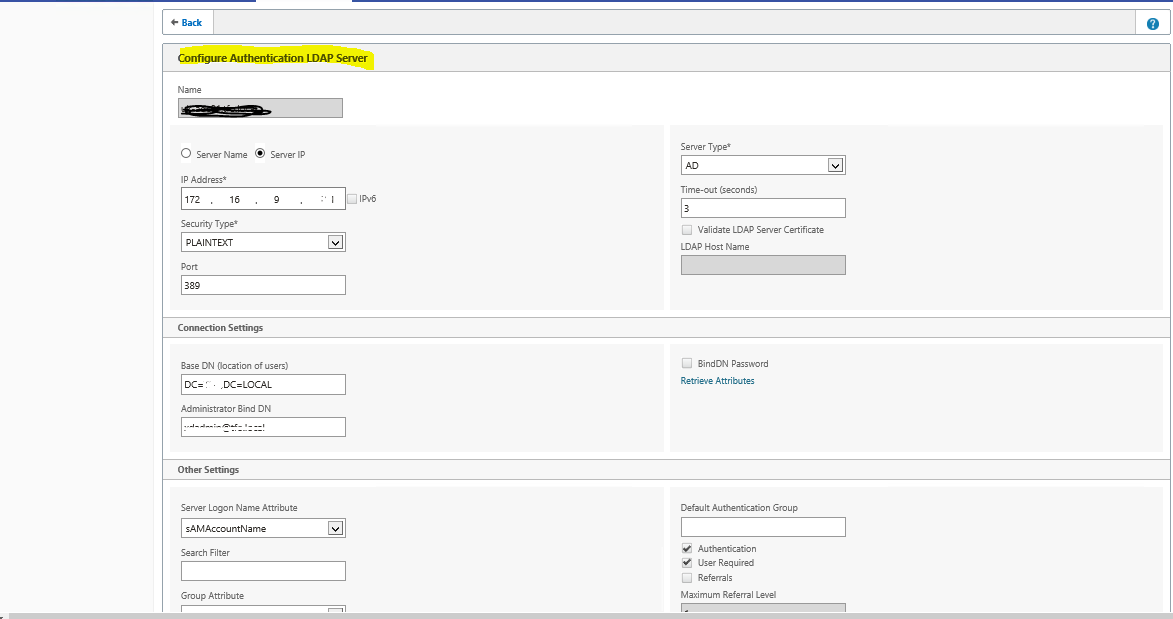
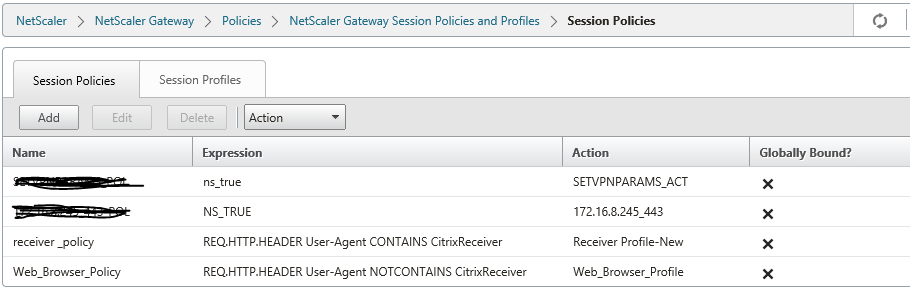
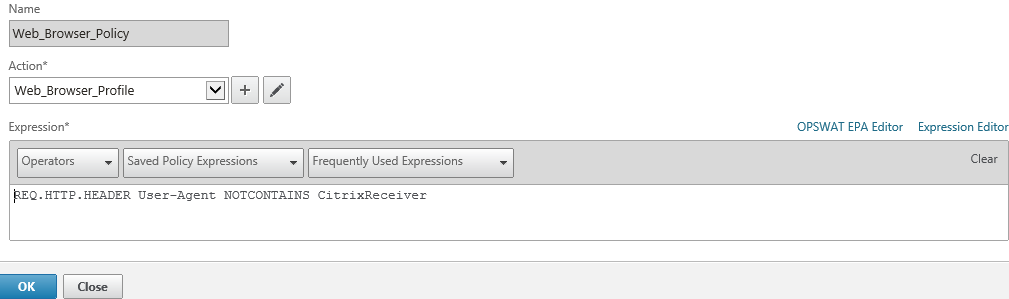
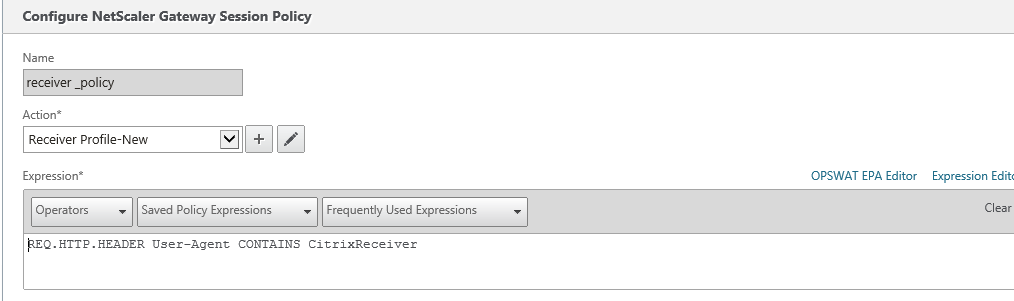
Delivery Controller |
Data Collector |
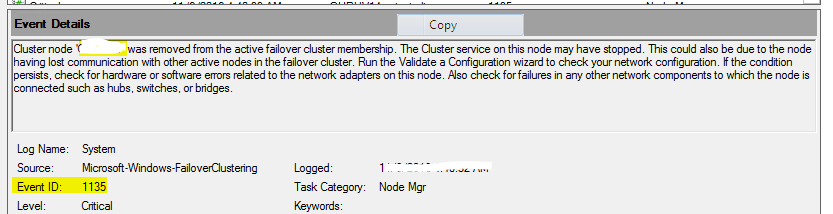
| No LHC | LHC(Local Host Cache) |
| Connection Leasing | No Connection Leasing |
| Pulls all information, static as well as dynamic from the central Site database | Has static as well dynamic(run-time) information cached locally |
| There is no direct communication between delivery controllers. No scheduled communication between the VDA’s and/or Site databases, only when needed. |
Communicates with the IMA store, Peer Data Collectors and its session Hosts(within its own zone) on a scheduled interval, or when a Farm configuration change has been made. |
| Is responsible for brokering and maintaining new and existing user session only. | Often hosts user session, but can be configured as a dedicated data collector as well. |
| Can have a different operating system installed then the server and desktop VDA’s | Need to have the same operating system as all other session hosts and DC’s within same Farm. |
| Core services installed only. The HDX stack is part of VDA software | Has all the XenApp 6.5 or earlier bits and bytes fully installed. |
| Zones are optional. When configured they do need at least one Delivery controller present. | Each Zone has one Data Collector. Having multiple data collector means multiple zones. |
| Election does not apply. Deploy multiple, at least 2 Delivery controllers per site /zone (again one per zone is the minimum) |
Can, and sometimes need to be elected. Configure at least one other Session Host per zone that can be elected as a Data Collector when needed. |
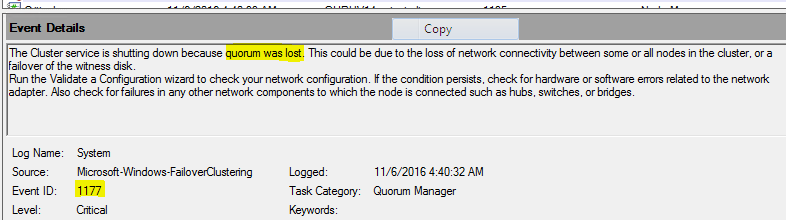
| When Central Site DB is down, no site wide configuration changes are possible. By default, Connection Leasing will kick in, enabling users to launch sessions which are assigned at least once during last 2 weeks prior to DB going offline. | when IMA Db is down, no Farm wide configuration changes are possible. Everything else continues to work as expected due to the LHC present on the Data Collectors and Session Hosts in each Zone. |
| A Delivery controller can have a direct connection(API) with a Hypervisor or cloud platform of choice. | Does not have any direct connection(API) with a Hypervisor or cloud platform management capabilities. |
| Almost all the communication directly flows through a Delivery Controller to Central Site DB. | Session Hosts as well as Data Collectors directly communicate with IMA database. |
| VDA’s needs to successfully register themselves with a Delivery controller. | When a XenApp server boots it needs a IMA service but it will not register itself anywhere. |